The Engineering Leader’s Playbook for Achieving Real ROI with AI
Engineering teams are shipping code faster than ever, but a growing share of their time is still consumed by testing, QA, debugging, and incident response. As systems become more distributed and interdependent, and AI writes more code than humans, every issue takes more time and people to fully understand.
Most organizations already have AI code generation tools in place, but the true ROI of these investments varies widely. Some teams see real gains in speed and stability; others struggle to quantify impact beyond incremental efficiency.
The reason for this variance is that many AI initiatives are still focused on code generation—but generation is no longer the constraint. The teams seeing ROI have shifted focus to where time is actually spent: code operations. This shift comes down to meaningfully reducing MTTR, preventing escape defects, and returning time to engineers.
This guide helps leaders evaluate the ROI of the AI tools they already use—and provides a tactical framework for improving that ROI over time. Learn which metrics matter, how to track them, and which operational shifts create the biggest returns in both the short and long term.
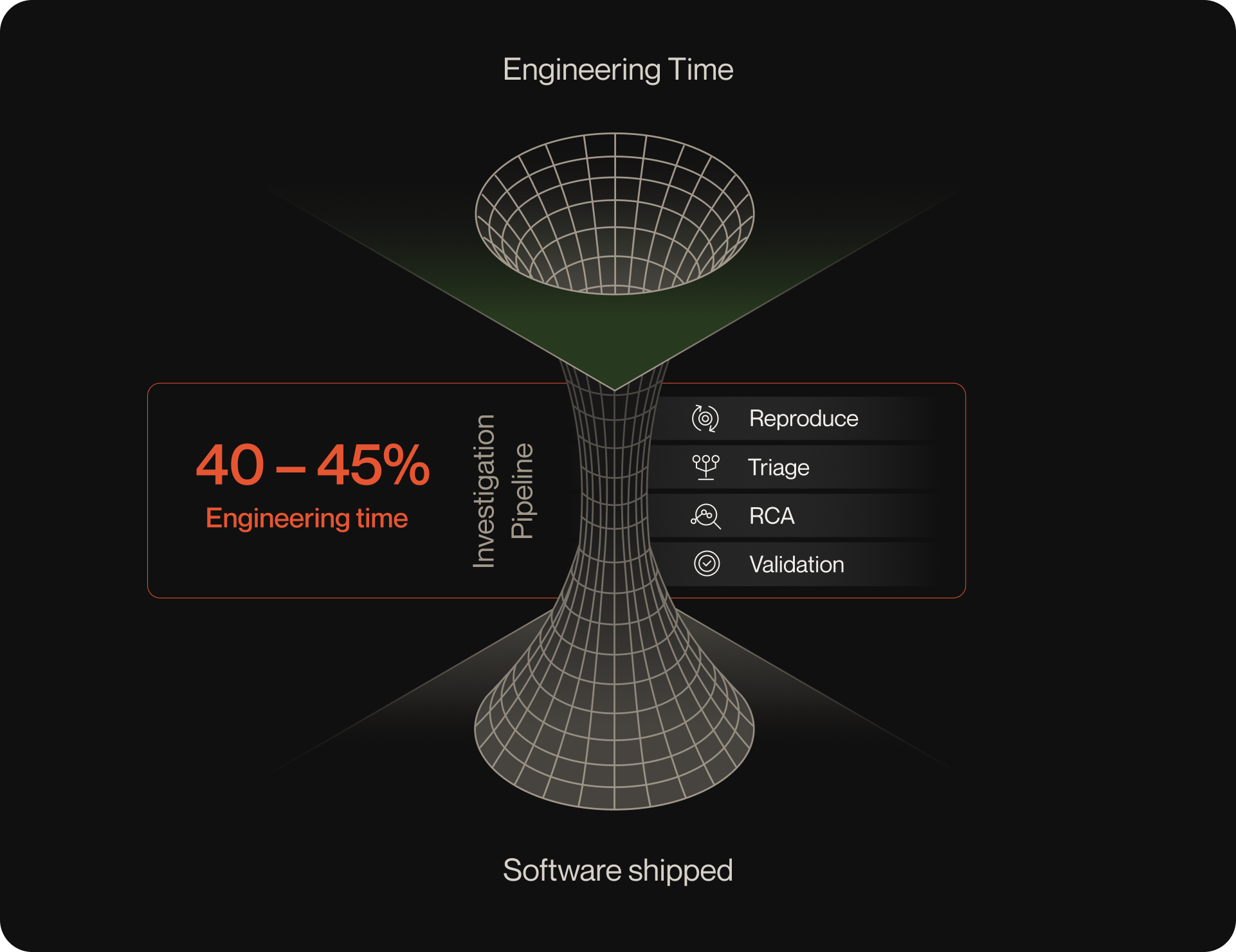
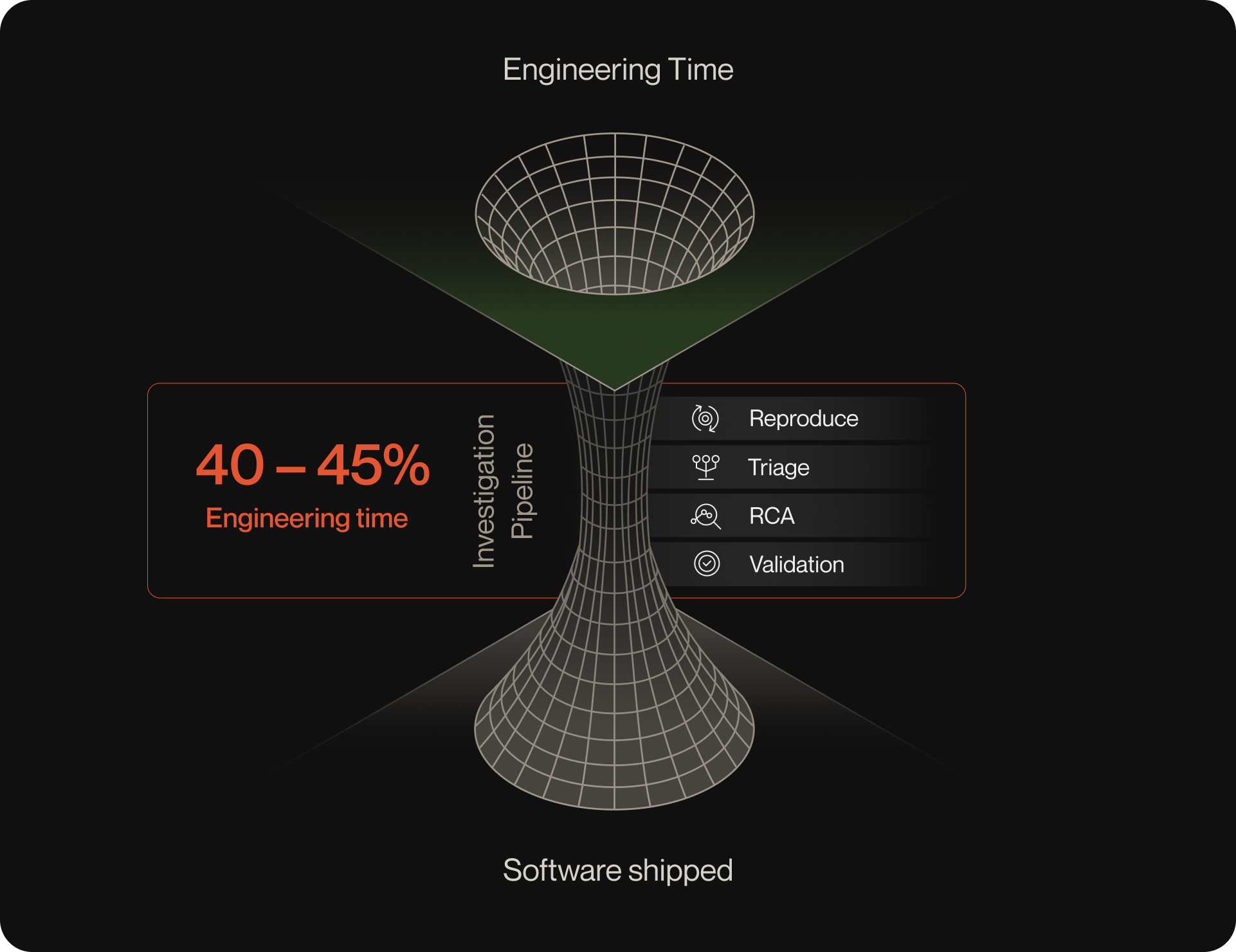
The hidden cost centers quietly eroding engineering ROI
Many of the forces that limit engineering ROI don’t show up as a budget line item. Instead, they surface as delays, handoffs, and repeated work that slowly chip away at delivery speed, support workloads, and team capacity.
At scale, these cost centers create measurable drag.
- Reactive debugging consumes significant engineering time
Studies show that 40–45% of engineering time is absorbed by troubleshooting and incident response. This time loss compounds: MTTR increases, backlogs grow, and roadmap work gets pushed out.
- Fragmented context creates investigation delays
Without unified context, engineers spend hours reconstructing incidents from logs, traces, PRs, tickets, and user sessions.
- Knowledge silos slow onboarding and create bottlenecks
Institutional knowledge is often locked in senior engineers’ heads. As systems grow more complex, scale becomes constrained by those who have context, stalling onboarding and investigations.
- Edge cases and regressions multiply as systems scale
Service interactions, asynchronous workflows, and configuration-driven behavior create unexpected edge cases. Regressions slip through and defect escape rates rise.

The engineering leader’s ROI measurement model
Most engineering leaders already track velocity, uptime, and deployment frequency. But AI tool ROI doesn't show up in those dashboards—it shows up in faster triage, prevented regressions, and fewer escalations. These improvements feel real but remain hard to quantify.
To make confident decisions about these investments, engineers need a shared model that translates those improvements into measurable outcomes. The following metrics provide that baseline, independent of which specific tools you use.
Time to first commit
Time to first commit measures how quickly new engineers ship their first meaningful code contribution. When AI tools surface the context developers need, like architectural relationships and semantic code understanding, new hires navigate complex codebases and contribute confidently without constant escalation. Faster onboarding reclaims senior engineering capacity and enables teams to scale without relying on experts.
MTTR (Mean Time to Resolution)
MTTR measures how fast teams move from detecting an issue to resolving it. Lower MTTR indicates that teams have better context at the point of investigation. Engineers spend less time on investigations, redirecting focus to planned work and minimizing customer-facing impact—all of which directly reduce operational costs and improve customer satisfaction.
Defect escape rate
Defect escape rate captures the percentage of issues that reach production. By reducing escape rates, teams avoid regressions tied to known failure patterns and production surprises from recent changes. This lowers support burden and reduces customer churn caused by preventable defects, improving margins and customer lifetime value.
Engineering capacity reclaimed
Engineering capacity reclaimed measures how many hours engineers get back each week as friction is removed from debugging, triage, and investigation workflows. Reclaimed hours can be reinvested into roadmap delivery, technical debt reduction, platform improvements, or experimentation. Over time, these gains compound into meaningful increases in roadmap throughput and more consistent delivery.
Change lead time
Change lead time measures how long it takes for a code change to reach production. When teams have trusted AI-powered QA and testing tools, they ship faster and catch more defects pre-deployment. This accelerated feature delivery supports market responsiveness—unlocking a lasting competitive advantage.
Customer satisfaction and stability
Fewer high-priority tickets, reduced escalations, and more stable releases drive higher CSAT and stronger retention. The result is stronger customer trust, retention, and long-term revenue growth—validating that internal improvements translate into real-world impact.
The engineering leader’s playbook for maximizing ROI with AI
Once leaders have a clear way to measure ROI, the next question becomes practical: what should we actually change to move those metrics in a durable way?
The biggest ROI gains come from improving how tools share context, how signals flow to the right teams, and how insights turn into action.
The following four plays make this actionable.
Pillar 1: Audit and improve how your existing tools share context
The first step is to audit where context breaks down today.
Look at a recent incident and trace how information moved from the initial alert to resolution. Ask yourself:
- Where did engineers stop and ask for more details?
- Where did they switch tools to piece together what happened?
- Where did reproduction depend on institutional knowledge rather than observable signals?
To close these gaps, focus on improving how existing tools share context. When AI systems operate on complete, reliable inputs—user behavior, runtime signals, and code changes—reproduction becomes faster and more consistent.
The impact shows up quickly in MTTR and reclaimed engineering hours. Issues can be diagnosed in minutes because the system tells a coherent story, transforming debugging from an exploratory exercise into a repeatable process.
Pillar 2: Validate code quality pre-production to prevent defects
The highest-ROI wins come from preventing defects before they reach production.
Integrate AI into your pre-deployment workflow. Use code and observability signals to identify high-risk PRs based on system-wide impact and historical failure patterns, then simulate execution paths to catch breakpoints before merge.
Look for fewer production incidents tied to recent PRs, shorter review times on high-risk changes, and a higher percentage of issues caught before deployment. These shifts reduce emergency fixes, stabilize release cycles, and create capacity for planned work. As the cognitive load drops across releases, ROI compounds.
Pillar 3: Automate triage and RCA to reduce noise and resolve customer issues faster
Even with unified context, many teams still rely on slow, manual processes for triage and root cause analysis of customer issues.
To avoid this, use AI to cluster related issues, surface user impact, and highlight the changes that are most likely to have introduced the defect. Ensure triage systems automatically attach relevant context—user sessions, error traces, and code diffs—so engineers can easily validate the root causes.
When triage improves, MTTR drops and engineering interruptions decrease. Teams filter out low-impact issues that consume engineering cycles, and high-priority problems reach the right engineers with full context immediately.
Pillar 4: Convert incidents into preventive intelligence
For ROI to grow, incidents need to become inputs to prevention.
Turn resolved issues into reusable detection logic, simulations, or tests that catch similar patterns earlier. Set a baseline for what percentage of monthly incidents are repeats. Measure how many regressions are caught by these new tests/sims before deployment—those represent direct ROI that’s attributable to this practice.
Each incident becomes a permanent safeguard. As your incident library grows, your detection coverage grows with it. Over time, the system gets better at recognizing the conditions that lead to failure before they recur.
This play catches issues before deployment and improves stability. Known failure modes are actively prevented, and validation becomes faster because teams aren’t re-learning the same lessons. Release cycles feel safer because the system builds memory, ensuring proactive resilience.
Pillar 5: Democratize resolution to reclaim engineering capacity
As systems become more observable and diagnosis accelerates, an important opportunity emerges: expanding who can resolve issues.
Give support, QA, and product teams deeper visibility into issue context to enable faster resolution without engineering intervention. Support teams identify known failure patterns, QA validates fixes with confidence, and product teams gain a clearer understanding of real-world behavior.
This democratization also accelerates onboarding across every team. New hires gain access to the same system-level context that previously lived only in senior engineers' heads—enabling them to resolve issues, validate fixes, and ship meaningful work independently.
This shift reclaims engineering bandwidth and improves customer satisfaction. Teams face fewer interruptions, new hires reach productivity sooner, and customers receive faster, more consistent responses—making the organization more resilient. At scale, this ensures engineering time is spent where it creates the most value, driving ROI.
What positive ROI looks like in practice
AI tool ROI doesn't show up as a single metric spike. Instead, watch for compounding improvements in how teams operate day-to-day.
- Accelerated delivery cycles: Teams spend less time diagnosing and recovering from issues. Debugging friction drops, change lead times shrink, and teams deploy more frequently with greater confidence. Releases become routine operations rather than high-risk events.
- Higher-quality releases: Fewer defects escape into production. When issues occur, they’re often familiar patterns your team has seen before. This stability reduces emergency fixes and creates space for deliberate, high-quality work.
- Reclaimed engineering capacity: Teams shift from firefighting to planned roadmap initiatives. Engineers spend more time on platform improvements and innovation, experience fewer interruptions, and report deeper focus and higher morale.
- Faster onboarding: New hires gain a clear, real-time view of system topology and behavior. Instead of manually reconstructing context, they understand dependencies and conventions immediately, so they reach first commit in days.
- Stronger cross-team alignment: Shared visibility into issue resolution reduces reliance on institutional knowledge. Handoffs improve, and collaboration between engineering, support, and product becomes smoother.
- Improved customer satisfaction: Faster resolution, fewer outages, and more predictable behavior build trust over time. Customers feel the difference in reliability and responsiveness—and that trust fuels retention.
Positive ROI doesn't show up overnight. Some improvements, like MTTR dropping as context improves, show up in weeks. Others, like a growing incident library that catches similar issues before deployment, compound over months.
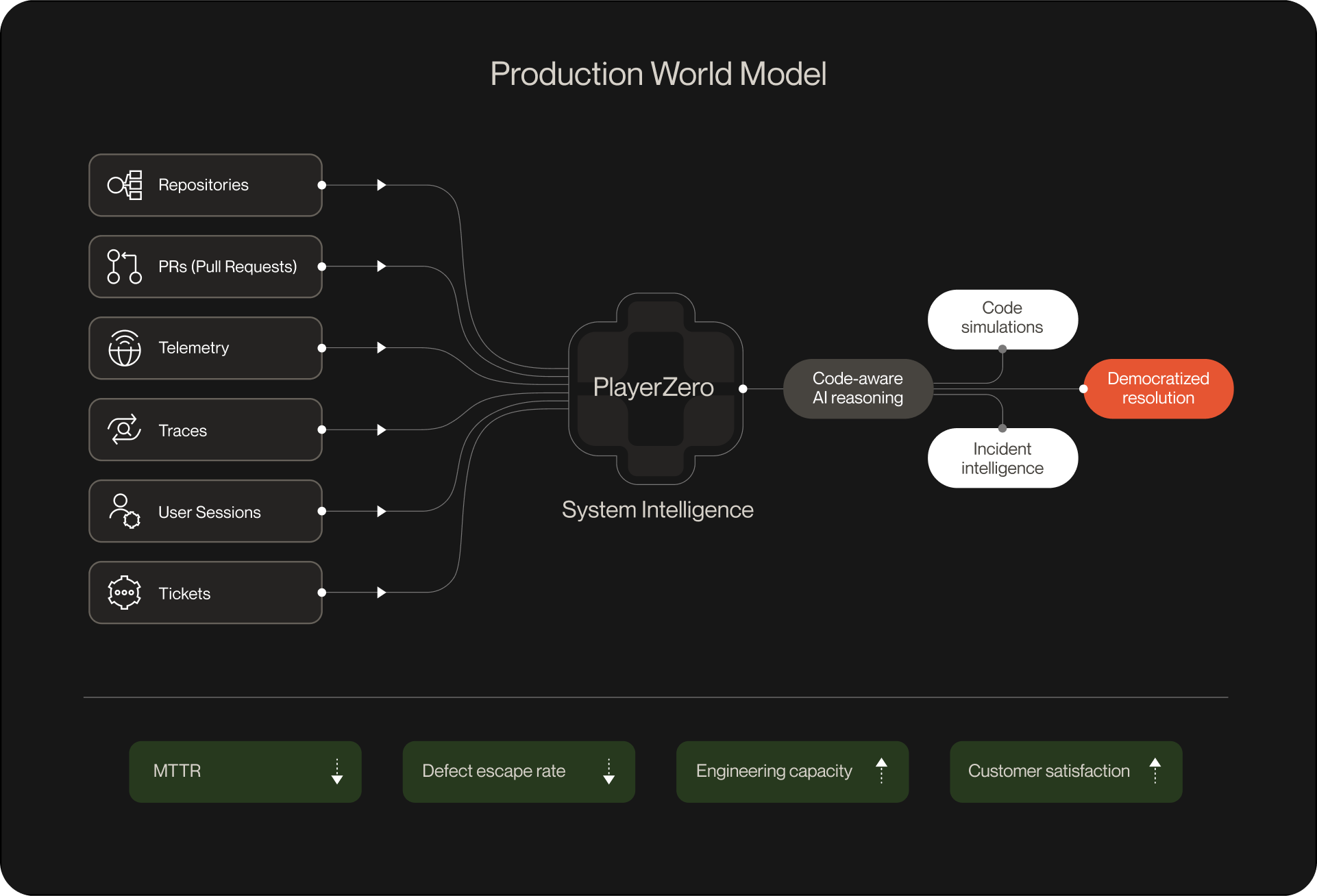
How PlayerZero uniquely delivers compounding positive ROI
What ultimately determines ROI is how much system context those tools can access—and how consistently that context is turned into action. PlayerZero strengthens existing tools by closing context gaps and turning isolated signals into repeatable, system-level insight.
System-level understanding rooted in real code and behavior
By correlating repositories, PRs, telemetry, traces, user sessions, and tickets, PlayerZero helps you ship fewer defects and shortens the path from symptom to root cause. This directly improves MTTR and accelerates workflows without sacrificing confidence. For example, Cayuse cut average time to resolution by 80% with this unified view, reclaiming engineering capacity and improving customer responsiveness.
Code-aware AI that reasons across architecture and history
PlayerZero assesses how changes affect downstream services, known failure patterns, and resolved incidents. This reasoning catches high-risk changes earlier, reducing defect escape rate and improving release quality.
Proactive defect detection via code simulations
Resolved incidents become inputs for prevention. With PlayerZero, teams validate fixes against execution paths pre-deployment and identify breakpoints before customers encounter them. This lowers regression frequency and strengthens stability metrics over time.
Democratized resolution across engineering, QA, and support
PlayerZero democratizes resolution across engineering, QA, and support by making institutional knowledge and system context accessible and actionable. Non-engineering teams gain visibility into how issues occurred, what code paths were involved, and which fixes apply—reducing escalations and boosting CSAT. Teams like Cyrano Video significantly reduced engineering time spent on support by enabling faster diagnosis and resolution across roles.
Together, PlayerZero’s capabilities create more than isolated wins. They compound, turning AI from a productivity aid into an operational advantage that strengthens engineering resilience.
ROI is no longer just about cost—it’s about clarity, capacity, and resilience
By changing how existing tools are used, connected, and measured, engineering leaders can turn insight into repeatable outcomes. By unifying context across tools, deploying AI where context density is highest, and converting incidents into prevention assets, engineering leaders reclaim capacity.
When teams consistently apply these practices—tracking ROI through MTTR, defect escape rate, reclaimed hours—they move faster, reduce production risk, and free up capacity for strategic work.
If you want to see how these practices can be operationalized within your existing tooling, you can explore a demo of PlayerZero.