What is Agentic SRE? The Next Evolution of Reliability Engineering
Modern software systems span hundreds of services, run across cloud-native environments, and change daily as new code ships. For SRE teams, this results in mounting pressure to deliver rapidly without compromising the reliability that customers demand.
This pace is exposing the limits of traditional approaches. Alert fatigue is widespread, and engineers spend more time firefighting than innovating.
Agentic SRE represents the next stage in reliability engineering, shifting from reactive response to proactive prevention. By embedding AI reasoning and continuous learning directly into the software lifecycle, agentic SRE can help teams cut through the noise, address root causes, and build systemic reliability into every release.
Why current SRE approaches are reaching capacity
Even the most experienced SRE teams are running into scale limits. Modern environments generate more signals, dependencies, and customer demands than human-driven processes can keep up with.
Foundational practices such asrunbooks, monitoring, and incident response frameworks remain critical, but at enterprise scale they begin to strain. What once ensured stability now leaves teams struggling to keep pace with the volume and velocity of change.
The bottlenecks are clear:
- Knowledge silos—critical context lives with a handful of senior engineers. When they’re pulled into every major incident, new features stall, and the team becomes dependent on tribal knowledge.
- Slow triage—a spike in alerts from microservices or customer-facing endpoints can take hours to correlate across logs, tickets, and monitoring dashboards, delaying the root cause analysis.
- Symptom-chasing—a memory leak or API timeout is patched in production, but without understanding the underlying regression, the issue resurfaces weeks later under a different load.
The result is predictable—more engineering hours consumed by reactive work, fewer devoted to building new capabilities.
Why reliability needs a new model
Compounding resources or tooling can’t keep pace with the increasing complexity. Hiring additional SREs or layering on new monitoring platforms may ease short-term pain, but it often adds cost and noise without addressing the root causes of instability.
Modern systems span hundreds of distributed services, generate thousands of code changes each week, and operate in constantly shifting cloud-native environments. Human-driven processes can’t analyze every regression, correlate every alert, or keep pace with this velocity.
The2025 SRE Report underscores the strain: site reliability teams now spend a median of 30% of their time on toil, up from 25% the year before.
The tradeoffs are stark. Teams can’t test or monitor everything. Even small oversights, such as a low-frequency edge case, a misconfigured API, or a regression in an obscure service, can cascade into customer-facing failures. When failures occur, the resulting cost is significant. Thelatest research shows the average outage in 2024 costs $14,056 per minute, and up to $23,750 per minute for large enterprises.
In addition, more than 20% of enterprise code is now AI-generated, and that share is growing. The risk surface is expanding faster than teams can respond.
That’s why reliability can’t remain a downstream, reactive function. It must move upstream, embedding systemic quality into the development lifecycle so that prevention, not just faster response, becomes the norm.
Systemic quality: the differentiator
Decades of SRE discipline have driven best-in-class service uptime and reliable recovery in traditional production environments. Foundational practices like incident response, runbook automation, and postmortem culture enabled teams to keep systems stable even as architectures grew more distributed.
However, persistent bottlenecks remain. Knowledge silos slow collaboration, triage drags on, and teams find themselves stuck in cycles of repetitive firefighting. These approaches help teams recover from incidents, but don’t prevent them from happening in the first place.
Many current solutions also optimize for the wrong outcomes. Observability platforms surface more signals, and SRE practices reduce mean time to resolution (MTTR), but neither addresses root cause resolution. As the Google Cloud team notes, this focus on symptoms can distract SREs from the underlying causes that truly improve reliability.
Systemic quality flips the script. By embedding prevention and continuous learning into the development lifecycle, teams reduce the opportunities for defects before they ever reach production. The payoff is tangible:
- Fewer escalations: Support and engineering teams spend less time on urgent incident response, enabling smoother customer experiences and reducing operational stress.
- Lower defect escape rates: More issues are caught upstream, so fewer bugs reach customers, driving higher product quality and minimizing costly hotfixes and rework.
- Expanded capacity for innovation: With less time consumed by firefighting, engineers regain bandwidth to focus on new features, product improvements, and strategic initiatives.
And the impact is quantifiable. At Cayuse, adopting PlayerZero’s predictive software quality platform prevented 90% of customer-facing issues and cut resolution times by 80%, giving teams back valuable time to build, not just fix.
What is agentic SRE?
Agentic SRE is the next evolution of reliability engineering. Purpose-built to handle the scale and complexity of modern, distributed systems, it seeks to apply AI in accelerating the reactive response to reliability issues and build toward proactive, systemic prevention.
By breaking down fragmented operational context, automating cross-system analysis to speed root cause discovery, and systematically reducing the volume of recurring incidents, agentic SRE tackles the very challenges that limit traditional approaches.
Agentic SRE combines three core capabilities:
- Cross-system AI reasoning: Correlates signals across code, tickets, telemetry, and user sessions. Instead of surfacing another stack of alerts, it proactively suggests remediations, factoring in business impact, code dependencies, and historical issue patterns, so teams can cut through noise and focus on high-impact fixes.
- Adaptive learning across changes and incidents: Continuously refines its understanding with every environment change, release, and production event. A fix for a memory leak in one service, for example, can automatically inform safeguards across other services with similar risk factors.
- Goal-driven remediation: Goes beyond alerting to recommend concrete next steps, such as rolling back a risky commit, flagging regression risk before a configuration change, or routing ownership to the right team, so issues are not just detected but resolved with minimal delay.
The result is a feedback loop that continuously reduces the defect surface area and stops recurring issues before they affect customers.
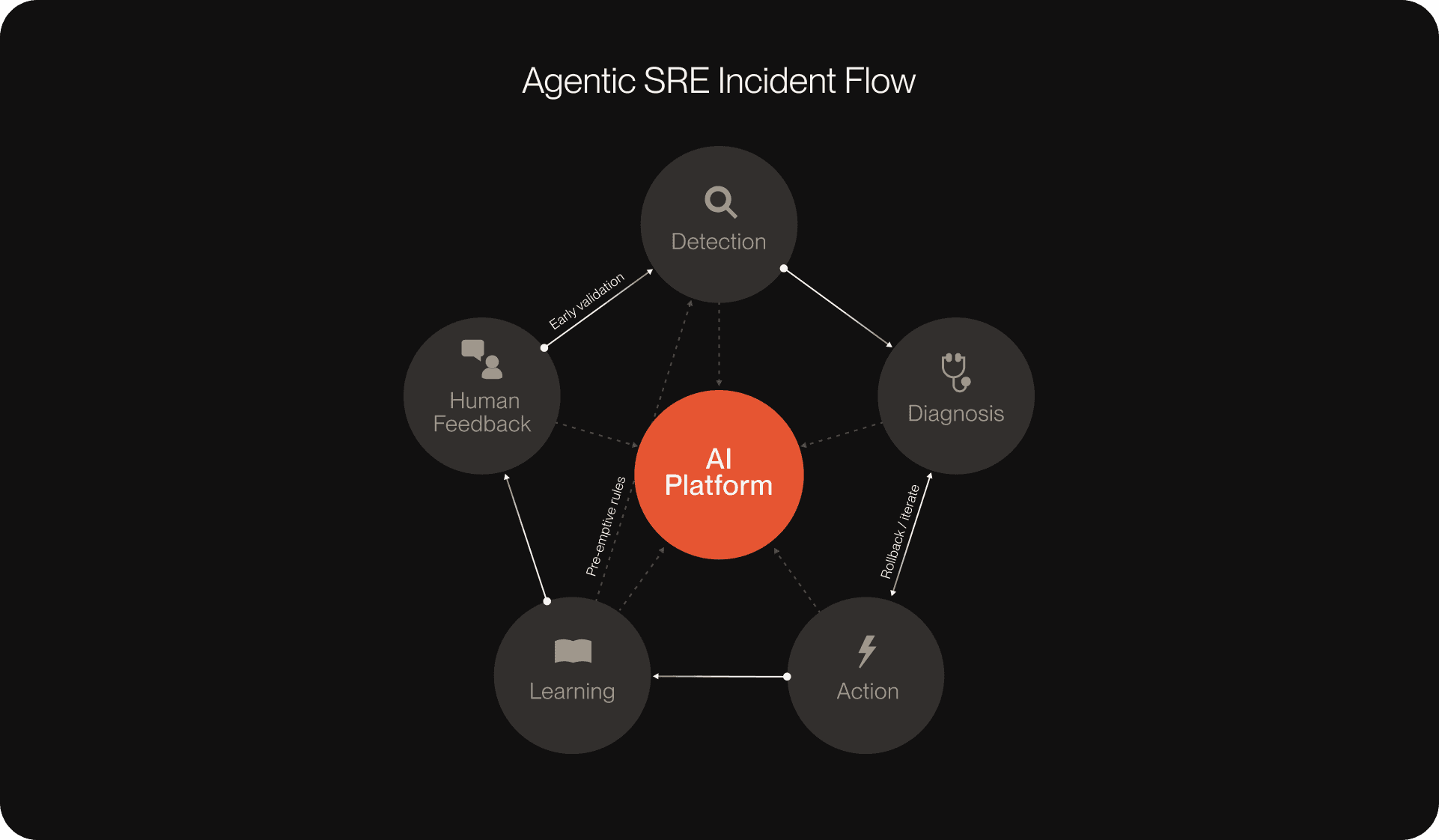
And importantly, this isn’t about removing humans from the loop. Agentic SRE works as a hybrid model where AI runs continuously at scale while engineers provide oversight, validation, and strategic direction. This balance ensures trust, accountability, and the governance controls enterprises require.
Addressing skepticism and implementation challenges
As with any emerging technology, early skepticism around agentic SRE reflects legitimate concerns about vendor overpromising. Engineers have seen “autonomous” reliability tools marketed as turnkey solutions, only to discover they falter in real-world production where context, trust, and oversight are critical. These experiences fuel the caution we see in the community today.
There are also practical hurdles. Governance, security, and integration consistently rank as top barriers to adoption. In fact, recent surveys show that 75% of technology leaders cite governance as their #1 concern when deploying agentic AI in production. Governance in this context means having clear approval flows, audit logs, and rollback mechanisms so that engineers always remain in control.
Where the technology delivers today:
- Triage complex signals across incidents, configuration and telemetry
- Propose fixes based on observed patterns
- Automate repetitive responses that normally drain SRE time
- Reduce alert fatigue and escalation overhead
Where maturity is still evolving:
- Workflows requiring absolute correctness or human-verifiable compliance (e.g., aerospace, healthcare, finance)
- Ultra-low-latency or deterministic environments where predictability outweighs adaptability
This is why the path forward is about augmentation, not replacement. Mature agentic SRE should be seen as digital teammates that work tirelessly in the background, correlating signals, learning from incidents, and proposing remediations, while human engineers retain final authority. Trust, auditability, and escalation remain non-negotiable.
The most successful deployments are incremental. Teams often start with safe, bounded use cases, like automated triage or issue correlation in non-critical environments, before expanding to customer-facing workflows. By layering in adaptive controls and maintaining oversight, organizations can build confidence gradually.
Acknowledging this nuance builds credibility: agentic SRE may not suit every workflow today, but where adopted thoughtfully, it unlocks systemic quality far beyond what traditional methods can deliver.
How agentic SRE works in practice
To address these challenges, it’s important to clarify how the aspiration of mature agentic SRE will integrate into engineering environments—without forcing a disruptive “rip and replace” approach.
Agentic SRE seeks to fit seamlessly into existing workflows, connecting with infrastructure orchestration, ticketing systems, observability stacks, and collaboration platforms. By unifying these data sources into a single pane of glass, it would eliminate silos and reduce the back-and-forth that slows down resolution today.
It also runs on a hybrid oversight model. The AI operates continuously, correlating signals and proposing fixes, while engineers provide review, escalation, and approval. This ensures teams gain the benefits of automation without giving up the trust and accountability that reliability demands.
To implement effectively, organizations focus on four practical considerations:
- Change management: Adoption is gradual. Teams start with bounded use cases—like automated triage in staging or internal services—before extending to production-critical workflows.
- Training: Engineers are upskilled to partner with agentic tools. Instead of replacing expertise, the system augments it, giving less experienced team members more autonomy and freeing senior engineers from repetitive tasks.
- Governance frameworks: Clear rules define who approves agentic recommendations, when automation can proceed independently, and how rollback mechanisms ensure safe recovery.
- Metrics for success: Teams measure progress not only by MTTR, but also by change management failures, engineering hours saved, and improvements in customer-facing reliability scores.
When a system failure is reported, the agentic system immediately begins automated analysis. Instead of engineers combing through logs and swapping tickets across teams, the system automatically traces telemetry, configuration changes, and infrastructure events to isolate the likely regression.
It proposes a remediation, such as rolling back a recent commit or applying an infrastructure change, which the engineer reviews, validates, and deploys. What once consumed hours of debugging and cross-team coordination is resolved in minutes, restoring customer trust and giving the team more bandwidth to focus on roadmap work.
How PlayerZero goes beyond conventional agentic SRE
Many agentic SRE tools today focus on incident response automation, making alerts faster or automating steps in runbooks. While these approaches help reduce time-to-recovery, they don’t address the underlying bottleneck: preventing issues before they reach customers.
PlayerZero, the first predictive software quality platform, is designed to make systemic quality a practical reality for enterprise engineering teams. By focusing upstream on prediction and prevention—not just post-incident response—it enables teams to catch risks ahead of release, drive continuous improvement from every incident, and embed preventative reliability practices into the development lifecycle.
Here’s how PlayerZero extends beyond automation and conventional agentic methods—creating a measurable, proactive, and continuous approach:
- CodeSim (Sim-1): Uses predictive simulation to model how code changes will behave across large, distributed systems. By analyzing dependencies and runtime patterns, CodeSim highlights regressions before deployment, integrating directly into CI/CD pipelines so engineers can deploy confidently without waiting for manual testing.
- Contextual analysis: Correlates code, tickets, telemetry, and user data into a unified graph of the software stack. This allows the platform to automatically map code-related incidents and bugs to their root causes, reducing defect escape rates and eliminating the need for engineers to chase fragmented clues across siloed tools.
- Integrated learning: Continuously ingests new commits, production incidents, and telemetry signals, feeding them back into the system’s knowledge graph. Over time, this creates a feedback loop where recurring issues are recognized and prevented earlier, strengthening code quality with every release.
These capabilities have enabled companies like Cyrano Video to cut engineering hours on support by 80%, while empowering their Customer Success team to resolve 40% of issues without escalation. At Key Data, what once took weeks of debugging is now resolved in minutes, freeing developers to accelerate feature velocity and focus on innovation rather than backlog firefighting.
With these capabilities, PlayerZero does more than automate responses—it establishes a new standard for software reliability where reliability and prevention are integrated from the ground up.
From firefighting to prevention: your next step
Agentic SRE marks a shift from reacting to problems after they happen to preventing them before they occur. By combining AI reasoning, continuous learning, and systemic quality practices, it gives engineering teams the ability to stay ahead of complexity rather than drowning in alerts.
PlayerZero is pioneering the predictive software quality category, transforming reliability through predictive simulation, contextual AI, and end-to-end learning. This approach goes beyond agentic SRE approaches, allowing teams to measure, optimize, and trust software reliability at scale.
Instead of spending hours chasing down incidents, teams can resolve them quickly and move forward with confidence. That shift means fewer fire drills, more time for meaningful fixes, and the freedom to focus engineering capacity on innovation.
Book a demo to learn how PlayerZero helps your organization achieve systemic reliability and prevent incidents before they occur.