How to Scale Engineering Teams Without Scaling Their Problems
When engineering teams grow, so do the challenges. When teams scale, the promise of rapid innovation is real, but so is the risk of losing shared context and creating bottlenecks that slow everyone down.
For engineering leaders, the challenge isn’t just shipping more code, but how to do it without sacrificing understanding, agility, or team morale.
Scaling fuels innovation until invisible bottlenecks emerge. Knowledge silos quietly slow momentum, fragment context, and put quality at risk. This guide breaks down how these barriers form inside growing teams and how to anticipate, diagnose, and eliminate them to scale without losing clarity or speed.
The hidden cost of moving fast: how silos form
As engineering teams grow and specialize, silos form, scattering knowledge and eroding shared understanding. Communication falters, documentation lags, and engineers lose visibility into dependencies. This fragmentation leads to bottlenecks, repeated escalations, and short-term fixes that compound technical debt.
The immediate effects are lower code quality, slower onboarding, and duplicated work. Over time, silos undermine customer satisfaction, stifle innovation, and increase the risk of knowledge loss when key staff leave. Ultimately, persistent silos drive up technical debt and ongoing productivity losses, highlighting the need for greater transparency, collaboration, and shared ownership.
Debugging and maintenance: how silos delay resolution
The impact of silos is most acute during debugging and maintenance. As systems grow, issues span multiple services. Engineers must navigate a maze of dependencies with limited visibility, relying on the knowledge of a handful of senior staff. Teams dig through code and services with sparse documentation, and even minor issues can escalate into major bottlenecks, stalling progress.
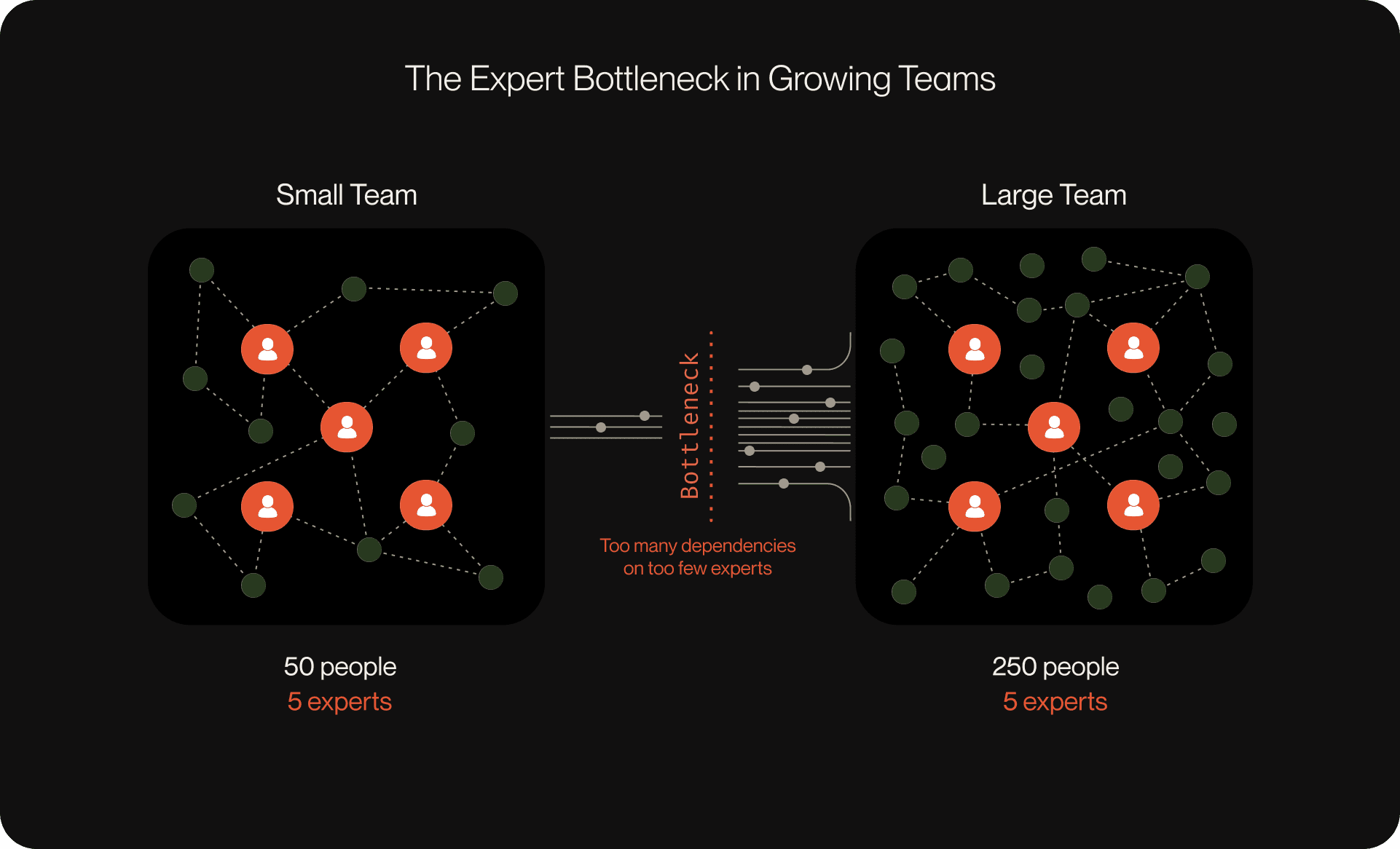
This overreliance on tribal knowledge is one of the most stubborn challenges in scaling engineering organizations. In a 50-person team, you might have five true experts — yielding an accessible 1:9 expert-to-team-member ratio. But as the team grows to 250, even with deliberate effort, the number of experts rarely grows proportionally. Instead of one expert for every nine people, you now have just five experts for 245 others — a 1:49 ratio. This shift means experts become severe bottlenecks, and when any expert leaves or takes time off, the knowledge gap grows dramatically. As a result, institutional expertise becomes exponentially harder for most of the team to access.
The impact is immediate and disruptive: quick fixes can turn into multi-day fire drills, pulling engineers from planned work and derailing timelines. Teams scramble to reconstruct lost context, productivity stalls, and critical issues can linger unresolved. Over time, this reactive cycle drains morale, increases risk, and makes it nearly impossible to sustain consistent delivery.
This isn’t just a technical issue — it’s organizational. Without shared context, support struggles to resolve issues, product teams can’t define features, and new hires face a steep learning curve. The result is more time spent chasing context, less time building value, and a growing drag on the entire organization.
Why traditional fixes don’t solve silos
Organizations often try to address these problems with more training, lunch-and-learns, or overlay teams like Site Reliability Engineers (SREs) or DevOps. But these solutions rarely scale. Lunch-and-learns are usually poorly attended. SREs and DevOps teams are expected to magically have all the answers, but they’re just as overloaded. Surface-level fixes — like more meetings or new documentation — address symptoms, not the cause.
The real check on whether knowledge is being shared is when something goes wrong — a major outage, a critical bug, or a customer-impacting incident. The root cause is often a lack of shared context, but the fixes are rarely systemic.
To break down silos, organizations must integrate contextual knowledge seamlessly into everyday engineering workflows, ensuring teams have the insights they need exactly when and where they work.
5 proven strategies for building shared context at scale
Organizations must treat knowledge management as a technical problem, not just a cultural one. Here are five steps to put that idea into practice:
1: Understand the true technical context
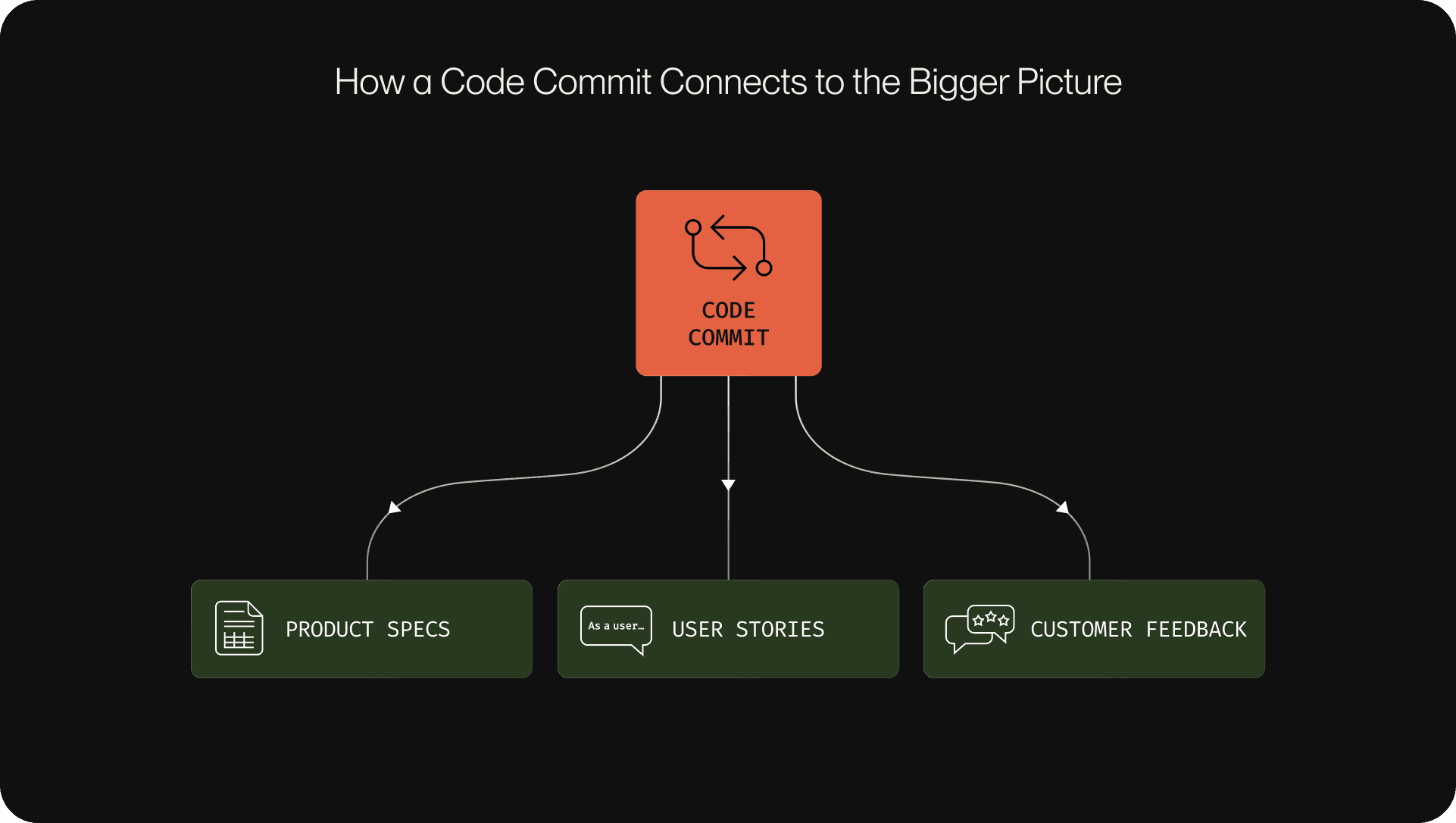
Go beyond code analysis to connect engineering work with business impact and user experience.
- Link code to relevant documentation, product specs, and customer-facing materials.
- Use tools to associate code changes with the original intent behind features or bug fixes.
- Encourage teams to annotate pull requests and code reviews with business context and expected user outcomes.
- Review these connections regularly during sprint planning and in retrospectives.
Why this works: Engineers gain a deeper understanding of how their work affects users and the business, leading to better decision-making and faster debugging. This approach also helps manage technical debt by ensuring changes align with long-term business goals.
How to apply this: Start by mapping your most critical code paths to related specs and documentation, and review these links in your next sprint planning.
2: Aggregate contextual data
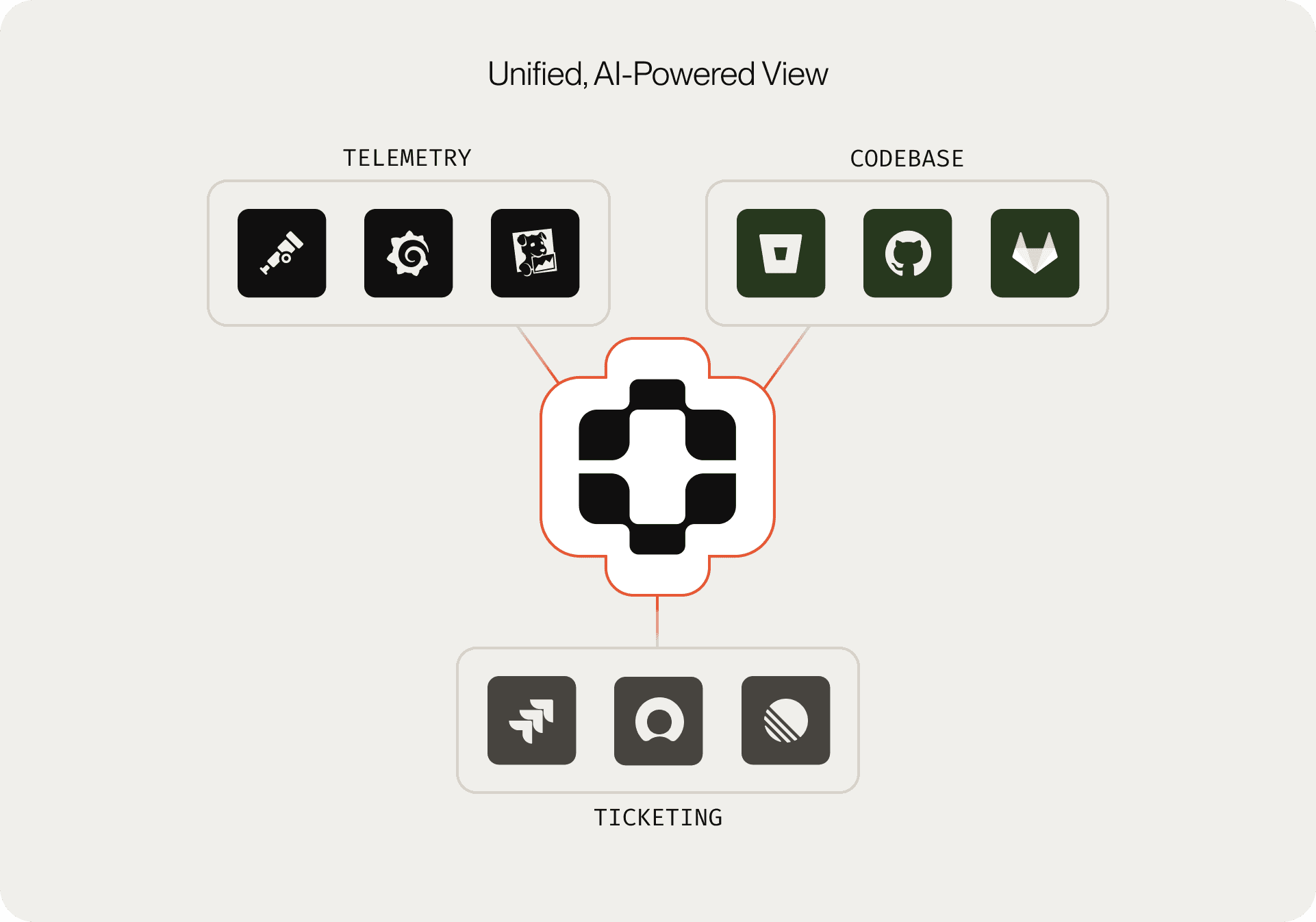
Once you’ve established technical context, unify all sources of truth for a holistic, real-time view of your system.
- Integrate code repositories, documentation, ticketing systems (like Jira), and customer support platforms.
- Set up automated data collection from real-time telemetry and monitoring tools.
- Centralize this information in a searchable, AI-powered platform.
- Encourage teams to use this unified view for debugging, incident response, and planning.
Why this works: Bringing together all relevant data cuts through assumptions, accelerates root-cause analysis, and ensures teams are working from the actual state of the system, not outdated or siloed information. This comprehensive approach reduces firefighting and supports proactive problem-solving.
How to apply this: Pilot a unified dashboard that aggregates code, tickets, and telemetry for a high-priority service this month.
3: Integrate customer and internal tickets
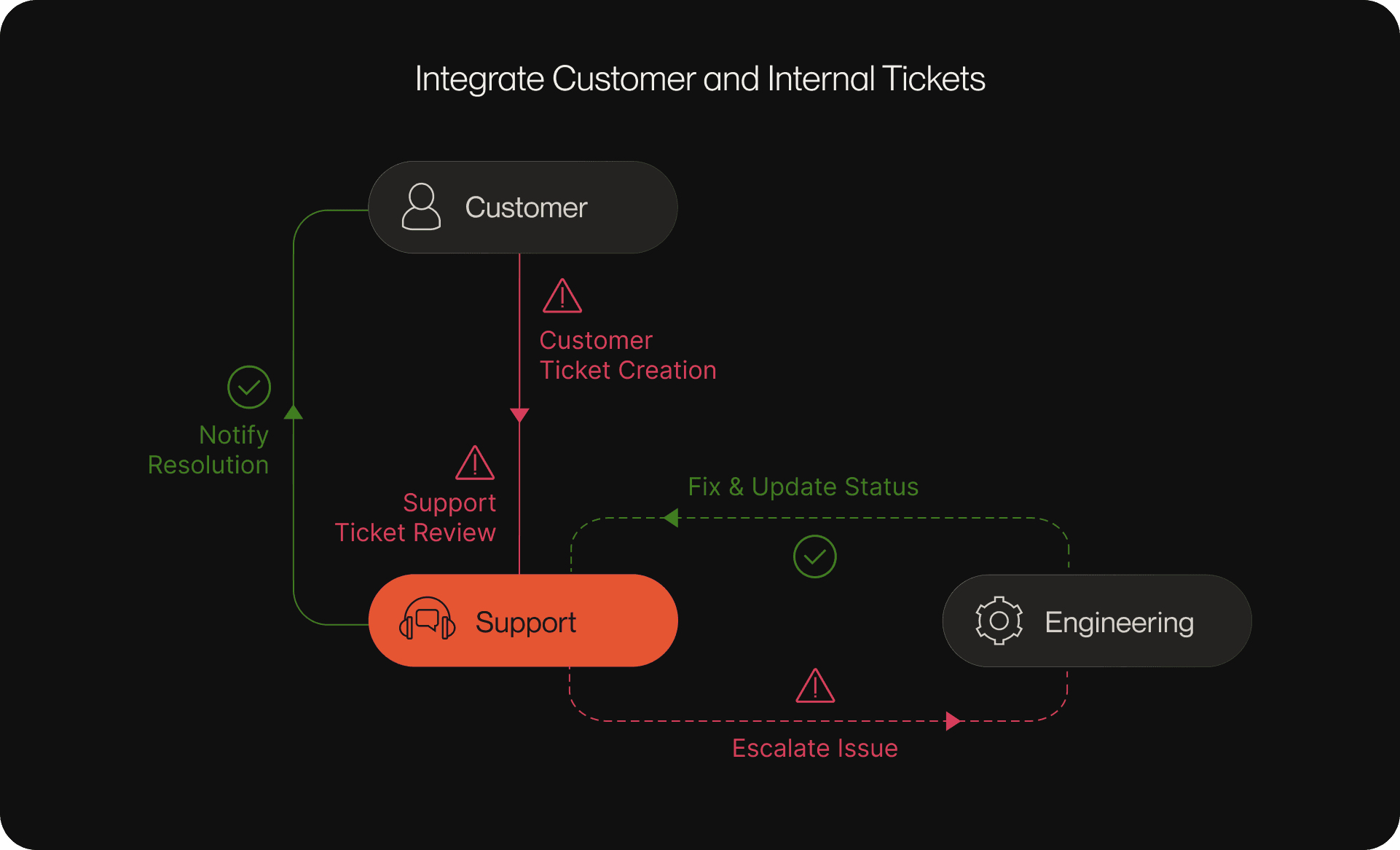
Once you have a unified data foundation, connecting what customers report with engineering workstreams closes the feedback loop and accelerates resolution.
- Aggregate customer-facing tickets (bugs, feature requests, support issues) in a central system.
- Map each ticket to relevant code owners, services, or internal tasks using AI-driven tools or manual triage.
- Regularly review and prioritize these tickets alongside internal backlogs during sprint planning.
- Track resolution progress and share outcomes with both customers and internal teams.
**Why this works:**Linking customer feedback directly to engineering tasks ensures urgent issues are addressed quickly, reduces duplicate work, and improves alignment between support and development.
How to apply this: Start by piloting a workflow that links top customer tickets to engineering owners for your most critical product area.
4: Invest in real-time observability
After closing the feedback loop, surfacing live system data empowers teams to spot and fix issues before customers are impacted.
- Deploy observability tools that capture logs, traces, and metrics across your stack.
- Set up dashboards and alerts for key performance indicators and user-impacting errors.
- Integrate observability data with ticketing and incident response systems.
- Review real-time data during daily standups and post-incident reviews.
**Why this works:**Real-time observability enables proactive problem detection and resolution, reducing the volume of high-priority tickets and improving customer satisfaction.
**How to apply this:**Identify your top two customer-impacting metrics and configure real-time alerts.
5: Prioritize usability and ergonomics
Even the best tools are only effective if everyone (not just experts) can find and use critical context.
- Audit current tools and workflows for usability barriers (e.g., complex navigation, unclear search).
- Simplify interfaces and provide guided onboarding for new users.
- Encourage feedback from a diverse range of team members, not just power users.
- Regularly update documentation and provide accessible training resources.
**Why this works:**If finding context is easy and intuitive, more team members will use the tools, reducing knowledge gaps and speeding up resolution. When usability is neglected, knowledge remains siloed, and only a few experts can effectively troubleshoot.
How to apply this: Run a usability test with new team members and implement at least one improvement based on their feedback.

How to build a culture of shared context
While technology can help surface information, culture sustains shared context over time. Creating a culture of shared context isn’t just about tools — the daily habits and values that teams practice ensure knowledge flows freely and context remains accessible. Here are concrete ways to build and maintain that culture as complexity grows:
- Foster cross-functional collaboration between engineering, product, and support to share diverse perspectives and context early, reducing misunderstandings and rework.
- Use blameless postmortems to surface hidden dependencies and improve documentation, so teams can learn from incidents and strengthen collective knowledge.
- Continuously review and update knowledge-sharing practices to keep processes relevant, address knowledge gaps, and help teams adapt to change effectively.
By embedding these habits into your culture, you create an environment where context is always accessible, empowering teams to move faster, solve problems proactively, and sustain high performance as you scale.
Scaling teams with confidence
Knowledge silos and bottlenecks aren’t inevitable. When knowledge management is treated as a technical challenge — and supported by the right tools and culture — engineering teams can scale without sacrificing speed, quality, or morale. That means more time building, less time searching, and teams ready for what’s next.
Achieving this level of clarity and momentum takes more than process — it demands a platform purpose-built to unify context across your organization.
PlayerZero’s AI-powered platform unifies teams and workflows, transforming how companies tackle debugging, ticket resolution, and knowledge sharing at scale.
- AI-driven ticket-to-code mapping: PlayerZero automatically links support tickets to the exact lines of code, commits, and owners responsible, streamlining root-cause analysis and eliminating manual guesswork. For Cayuse, engineering teams identified and resolved 90% of issues with PlayerZero before they reached customers, reducing average time to resolution by 80%. This rapid clarity freed engineers to focus on proactive improvements, while customer satisfaction scores climbed.
- Continuous accumulation of working knowledge: Every resolved issue becomes a reusable pattern in PlayerZero, enabling the platform to suggest solutions for similar problems in the future. At Cyrano Video, PlayerZero helped the Customer Success team resolve 40% of issues without engineering escalation, saving two hours per employee per week and reducing engineering time spent on debugging by 80%. The result: faster fixes, stronger collaboration, and more time for innovation.
- Automated fixes and real-time insights: PlayerZero proposes candidate patches and surfaces live code dependencies, historical fixes, and relevant documentation for everyone, not just domain experts.
- Unified, cross-silo context: PlayerZero connects user issues, telemetry, commit history, and documentation directly to the code, making critical knowledge accessible and actionable for every team member. This breaks down bottlenecks, transforms tribal knowledge into shared intelligence, and empowers teams to deliver better products at scale.
Ready to break through bottlenecks? Book a demo to discover how PlayerZero unlocks faster debugging, fewer escalations, and proactive problem-solving for your entire engineering team.