Revealing the Hidden Costs of Codebase Complexity
Friday afternoon. The company’s sales dashboard crashes without warning. What should have been a quick patch spirals into an all-hands emergency: operations, backend, and data teams swarm the war room. But their efforts circle through endless logs and scattered indicators, never quite pinpointing which service triggered the failure. Hours tick away, escalating uncertainty, deadlines slip, and revenue hangs in the balance.
This scenario is no outlier; it’s an increasingly common symptom of a much deeper, systemic issue. As enterprise software systems grow exponentially, fueled both by traditional human development and the surge of AI-generated code, the foundational understanding that once held teams in control of their systems is rapidly eroding.
Each new release compounds this complexity, multiplying risk across operations and customer experience. Fixes drag into the late hours, feature launches are delayed, and customer frustrations grow after every breakdown.
This breakdown stems from a fundamental issue: what happens when organizations lose control of their codebase?
What happens when you don’t understand your code
In such environments, firefighting becomes routine. War rooms assemble for days-long debugging marathons, yet root causes remain elusive—a consequence of shallow system knowledge. Without explicit, system-wide visibility, engineers waste precious time chasing symptoms instead of addressing fundamental flaws.
This confusion creates unhealthy reliance on senior engineers who understand the legacy code’s labyrinth. These experts become operational bottlenecks and single points of failure, especially when facing multiple crises. Meanwhile, problems that could be nipped early fester undetected, leading to costly, visible failures.
For instance, consider a multi-team firefight triggered by a checkout flow outage. The tightly interconnected nature of features causes miscommunications and missing context to cascade. This turns what should be a swift fix into a costly, prolonged escalation across multiple silos, which can drag on for weeks as teams chase symptoms without clear system context.
In code environments with a mix of human and AI-generated code, shared context and accountability across features become even harder to maintain.
The hybrid challenge: Why codebase understanding breaks down
Modern enterprises face a new and unprecedented challenge: hybrid codebases composed of both human-written and AI-generated code. While AI accelerates feature development, its outputs often lack vital context, explanations, or documentation that human developers rely on. This opacity compounds difficulties with tracing code logic or spotting bugs.
Enterprise codebases change at breakneck speed. New code floods in faster than traditional review and documentation processes can keep pace, rapidly dating existing records. Manual documentation and informal handoffs become artifacts in a flurry of change, stretching resolution times and frustrating developers.
Knowledge fragments widely, scattered across contributors, teams, and geographies. Adding to the challenge is the immense time teams spend simply hunting for the right context or tribal knowledge. And when key people leave, they take critical institutional knowledge with them.
Manual processes cannot handle the dynamic, evolving nature of systems, nor identify hidden risks lurking in tangled code or dependencies. Static checklists and traditional QA are overhead-heavy and inadequate. They fail to surface the multi-layered behaviors that modern distributed systems produce.
These factors don’t simply challenge engineers—they expose entire organizations to amplified productivity declines and degraded customer experiences.
The business cost of shallow codebase understanding
The complexity crisis isn’t isolated to software teams; it’s a company-wide risk with tangible business consequences. A lack of codebase clarity undercuts company revenue, agility, and brand reputation.
- When teams get bogged down in firefighting and duplicated effort, feature delivery slows, and crucial go-to-market windows slip. Markets reward speed, and these delays hand the competitive advantage to rivals.
- Customer trust erodes through repeated outages and lingering bugs that prolong downtime. Churn increases, and high-value partnerships start to fray under the pressure of unpredictability.
- Hidden technical complexity multiplies operational costs and complicates audits, compliance reviews, and acquisitions. Unexpected issues surface in integrations, adding delays and expense precisely when companies need smooth transitions.
- Engineering team burnout rises as workloads balloon, turnover accelerates, and institutional memory weakens. Instead of containing risks, stressed teams amplify them, sapping innovation and dragging down enterprise resilience.
When shallow understanding pervades, the issue is no longer purely technical: it’s a systemic business risk demanding comprehensive, enterprise-grade solutions.

Defining true codebase understanding for enterprises
Shallow code understanding looks like this: a developer reads a single file, makes a change, and hopes the rest of the system holds together. In practice, this means regressions slip through, fixes create new bugs, and teams end up firefighting issues that could have been prevented.
Deep code understanding flips this dynamic. Teams can see how a change ripples across system-wide dependencies, predict downstream impacts, and prevent regressions before they ever hit production. For example, PlayerZero’s Sim-1 engine analyzes 50x more code paths than standard test suites and runs 10-100x faster than manual review—enabling teams to surface issues and focus their efforts instead of burning cycles in the war room.
At enterprise scale, shallow understanding fails quickly: architectures evolve, teams turn over, and tribal knowledge disappears. That’s why true understanding has to be codified and automated, capturing how the system behaves across versions so context persists.
With this foundation, organizations can use AI-generated code safely, surface subtle defects earlier, and avoid the unpleasant surprises that derail deployments, frustrate customers, and weaken trust.
How modern platforms deliver system-level understanding
Today’s platforms close the divide between code complexity and business impact by connecting system-level visibility, predictive insight, and resilient knowledge transfer.
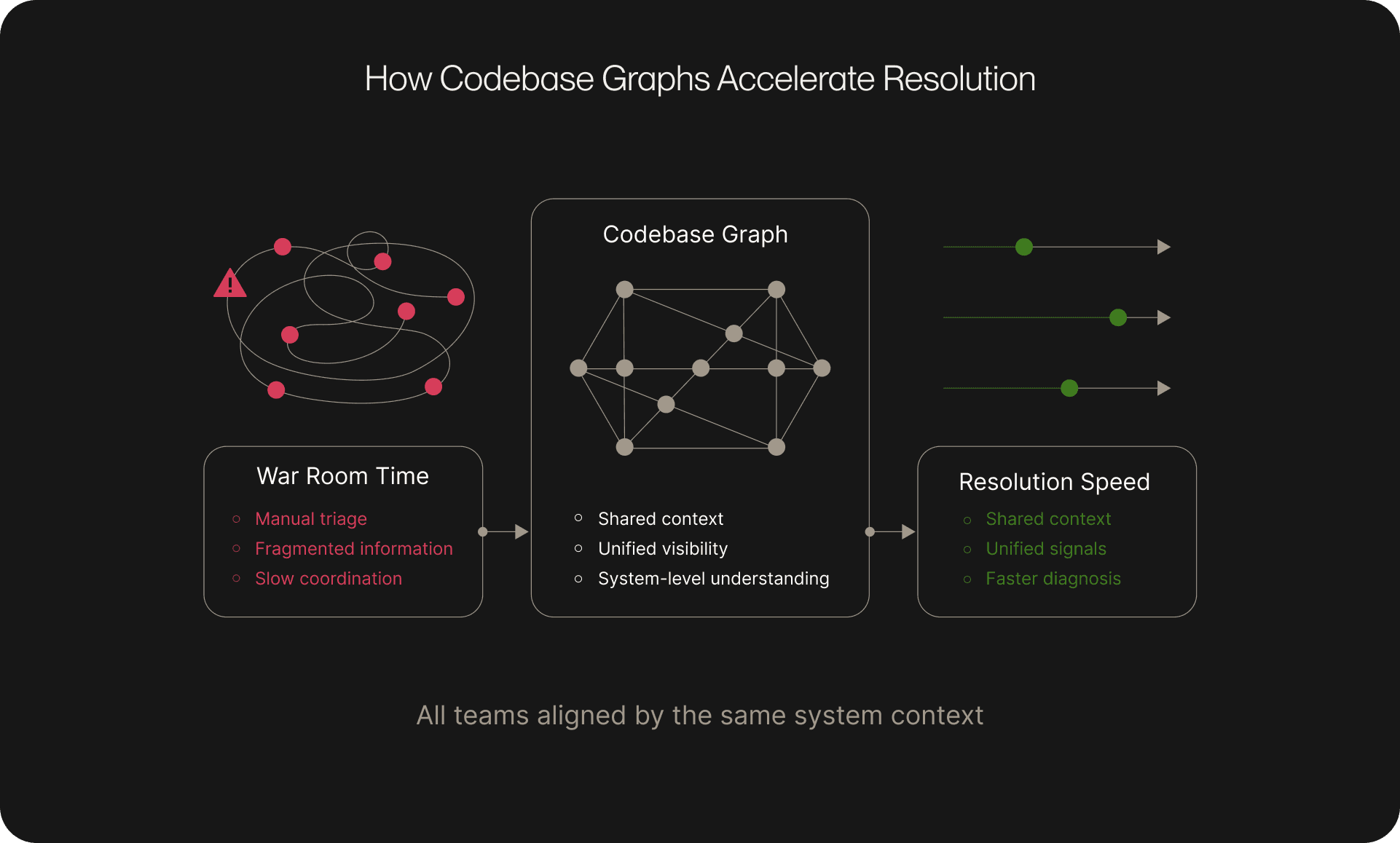
Dynamic visibility through AI simulation and continuous dependency mapping
Enterprises need more than static diagrams or out-of-date documentation—they need a living picture of how their systems behave. That’s where AI-driven simulation and continuous dependency mapping come in: they provide real-time visibility into how services interact and how changes ripple across the stack. This dynamic view illuminates hidden risks early, giving teams a chance to address them before they escalate into costly, customer-facing incidents.
PlayerZero delivers this capability through continuous AI-driven code simulation and always-on dependency mapping, uniting teams around a shared system map instead of fragmented context.
For example, when Cayuse integrated PlayerZero’s platform, they prevented 90% of potential incidents visible to customers. Breaking down silos and aligning teams on a single source of truth dramatically cut firefighting time and accelerated root cause analysis for the issues that did occur.
Predictive risk modeling for smarter testing and remediation
Traditional QA spreads testing effort thin, often wasting cycles on areas of the codebase that pose little real risk. Predictive risk modeling flips that approach by using statistical models to identify the code paths and modules most likely to harbor defects or cause outages. This lets teams redirect effort away from low-value checks toward targeted remediation that delivers greater stability with less time.
PlayerZero applies this approach directly, using predictive risk modeling to pinpoint the specific areas of the codebase most likely to trigger defects or outages, so engineering and testing resources focus where they matter most.
For instance, Cyrano Video slashed engineering hours tied to support escalations by 80% after PlayerZero pinpointed high-impact fixes, dramatically reducing churn and easing the load on support teams.
Connecting technical signals directly to business outcomes
Code quality isn’t just a technical concern—it directly shapes customer experience, revenue, and operational efficiency. Modern platforms close that gap by linking technical changes to business-level impact, showing leaders how engineering decisions affect outcomes that matter.
PlayerZero does this by correlating technical signals and code changes with customer experience and KPIs, giving leaders a clear view of how each release might influence revenue, retention, and operational efficiency.
With this clarity, engineering shifts from being seen as a cost center to becoming a strategic enabler, protecting customer value, safeguarding revenue, and accelerating growth.
Automated knowledge transfer and system-level insight
When only a handful of engineers know how a system really works, they become single points of failure. If those experts leave, or even just go offline during a crisis, projects stall, fixes drag on, and institutional memory evaporates. Codifying that knowledge at scale is the only way to break free from this risk.
PlayerZero tackles this by automatically capturing the “story” behind every code change, ticket, and incident resolution, then weaving it into a living knowledge base. Instead of tribal knowledge trapped in Slack threads or someone’s head, insight becomes searchable, connected, and actionable across the entire enterprise.
The result is faster onboarding for new engineers, smoother handoffs across teams, and greater resilience as teams scale. By turning past fixes into future foresight, PlayerZero helps enterprises move from fragile, person-dependent systems to durable, system-wide intelligence that sustains agility and continuity.
The path forward: predictive code quality
As codebases grow more complex and AI accelerates development, manual processes, static documentation, and reactive debugging simply can’t keep up. For enterprises, proactive quality management is no longer optional; it’s a strategic imperative.
The organizations that succeed will adopt system-level, predictive understanding across their entire software stack. With PlayerZero’s predictive software quality platform, codebase opacity transforms from a liability into an advantage, driving resilience, speed, and true business agility.
See how predictive code quality can turn complexity into a competitive advantage. Book a demo with PlayerZero today.
TL;DR
When enterprises lack deep codebase understanding, even the simplest investigative steps break down:
- What is happening? Outages and bugs surface without clear signals.
- Where is it happening? Teams chase symptoms across silos instead of pinpointing root causes.
- Who can fix it? Reliance on a handful of experts creates bottlenecks and delays.
- What do we need to do to fix it? Resolution stalls as fixes trigger new regressions.
With system-level visibility and predictive insight, these questions become straightforward to answer. PlayerZero equips teams with always-on code simulation, dependency mapping, and up-to-date knowledge of system behavior, so they can detect risks early, resolve incidents quickly, and prevent future breakdowns. The result: less firefighting, faster delivery, and more resilient customer experiences.