There's a demo that I give in PlayerZero that inevitably gets a big reaction. Whether it's incredulity or amazement, when people see PlayerZero CodeSim finding future defects in a pull request, there's always a "what?" or a "wow!" How can an AI platform predict the future? What it's actually doing is simulating all the possibilities. It's asking "what if?" It can do this because it has a complete understanding of how software actually behaves in production — not just what it's supposed to do.
How CodeSim Works: The Whiteboard Test
When we explain code simulation to engineers, we use a simple analogy. It works very much like how you or I would do it if we sat down and had a whiteboard and a marker and read the code out loud and said, okay, this happens here, what happens next? But with the ability to do it across your whole codebase.
Simulation is the test of understanding. If your system can't answer "what if," it's just a search index.
No containers. No infrastructure. No runtime. Just dry running through the code line by line, exactly the way a senior architect would manually trace through logic when debugging a complex issue.
This isn't about spinning up environments or building executables. It's about understanding intent, following logic, tracking state changes, and predicting outcomes. The kind of reasoning that separates experienced engineers from those still learning the system.
We've validated this approach across 2,770 production scenarios with 92.6% accuracy, maintaining coherence across 30 minute traces and 50 service boundaries. These aren't synthetic tests. They're real issues that broke production systems, captured as scenarios, then replayed as simulations. For a deeper look at how code simulation stacks up against traditional approaches, see Code Simulation vs. Static Analysis.
Why Simulation Requires Context Graphs, Not Search
Here's where most approaches break down. You can't simulate without understanding the entire system. And you can't understand the entire system by just indexing code or retrieving relevant snippets.
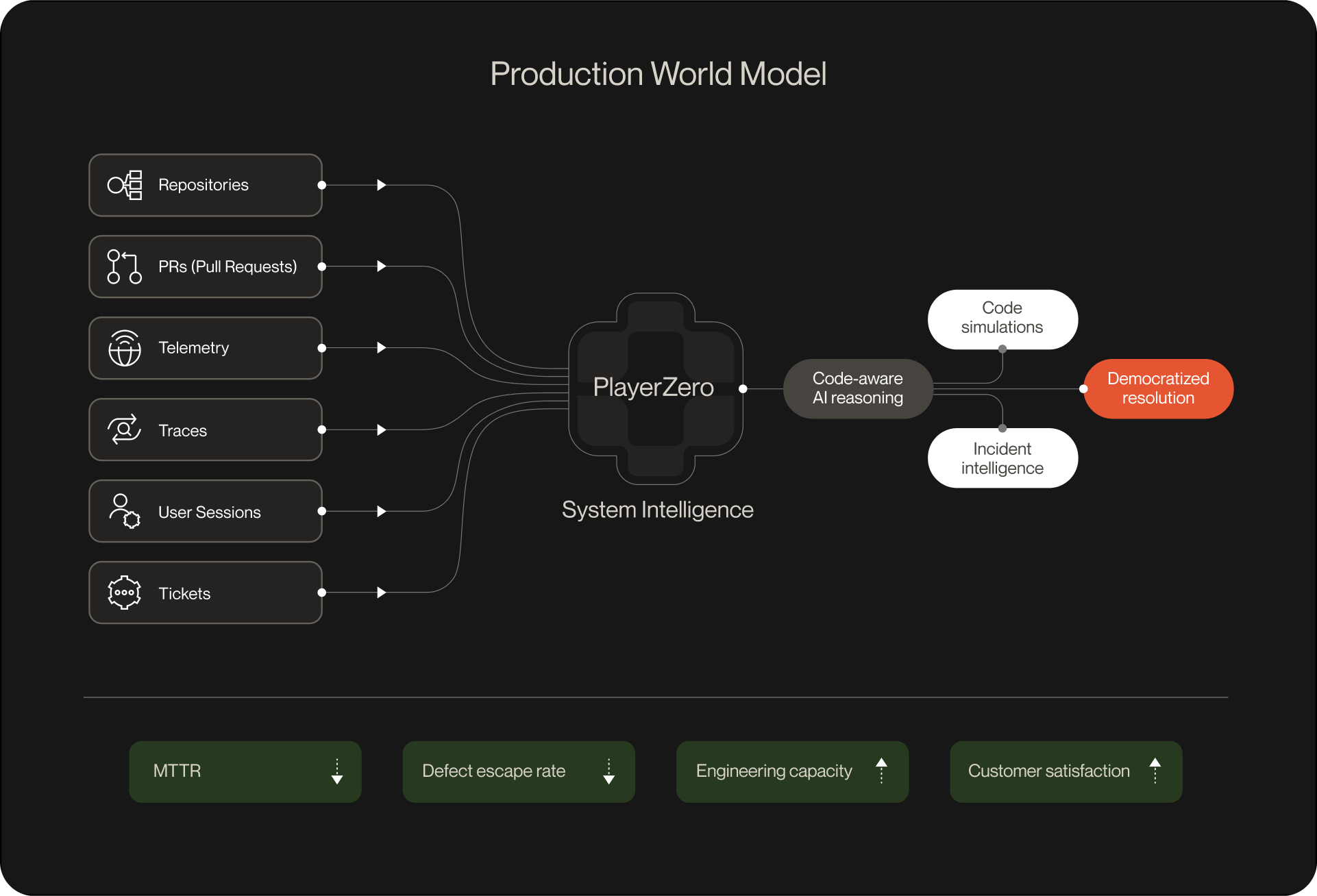
This matters because production exists in pieces today. Code describes what should happen. Observability tools see signals. Ticketing systems see problems. CI/CD sees changes. Every surface sees a slice. None maintain a coherent model of how the system actually works.
Traditional approaches treat this as a retrieval problem. Query the codebase, find relevant files, pass them to a model, generate an answer. That works for simple questions. It fails spectacularly for "what happens if we deploy this change?"
Context graphs solve a different problem. They don't just store what exists. They capture how things relate, how they've changed over time, and how they actually behave under real conditions. For a full explanation of how we build them, see Context Graphs: Building Engineering World Models for the Age of AI Agents.
When you ask "will this code change break production," the answer doesn't live in any single file or even any single repository. It lives in the relationships between code, configuration, deployment history, customer usage patterns, past incidents, and learned failure modes.
A context graph for production systems needs to model:
- Code and configuration: the intended behavior
- The problem stream: tickets, alerts, incidents, bug reports
- Runtime signals: telemetry data — logs, traces, errors where they exist
- Decision history: what broke before, how it was fixed, what patterns emerged
This creates something fundamentally different from a knowledge base. It creates a graph of how the system behaves, not just what it contains.
From Context Graphs to Engineering World Models
Once a context graph accumulates enough structure, it becomes something more valuable. It becomes a world model.
A world model is a learned, compressed representation of how an environment works. It encodes dynamics — what happens when you take actions in a specific state. It captures structure — what entities exist and how they relate. And it enables prediction: given current state and a proposed action, what happens next?
The robotics analogy makes this concrete. A world model capturing physics (how objects fall, how forces propagate) lets you simulate robot actions before executing them, train policies in imagination, explore dangerous scenarios safely. The better your physics model, the more useful your simulations.
The same logic applies to software systems. But the physics is different.
Organizational physics isn't mass and momentum. It's decision dynamics. How do escalations propagate? What happens when you change this configuration while that feature flag is enabled? What's the blast radius of deploying to this service given current dependency state? Which customers actually exercise this code path, and how?
State tells you what's true. The event clock tells you how the system behaves. And behavior is what you need to simulate.
How Engineering World Models Learn Without Retraining
World models solve a problem that the industry has been wrestling with for years: how do AI systems get smarter without constant retraining?
The standard framing asks: how do we update model weights from ongoing experience? That's hard. Catastrophic forgetting, distributional shift, expensive retraining. The path most teams pursue.
World models suggest an alternative: keep the model fixed, improve the world model it reasons over. The LLM doesn't need to learn if the world model keeps expanding.
This is what agents can do over accumulated context graphs. Each trajectory is evidence about organizational dynamics. At decision time, perform inference over this evidence: given everything captured about how this system behaves, given current observations, what's the posterior over what's happening? What actions succeed?
More trajectories, better inference. Not because the model updated, but because the world model expanded.
And because the world model supports simulation, you get counterfactual reasoning. Not just "what happened in similar situations?" but "what would happen if I took this action?" The agent imagines futures, evaluates them, chooses accordingly.
This is what experienced employees have that new hires don't. Not different cognitive architecture — a better world model. They've seen enough situations to simulate outcomes. "If we push this Friday, on-call will have a bad weekend." That's not retrieval. It's inference over an internal model of system behavior. It's also why reducing debugging time compounds in systems like this: the model already knows where the risk lives.
The Compounding Loop
World models become more valuable with every problem solved. Early in deployment, agents learn the basics: service dependencies, common failure modes, frequently broken flows. But as they handle hundreds of issues, they develop deeper understanding: subtle interaction effects, edge cases in specific customer configurations, patterns in how different types of changes introduce risk.
This creates a compounding advantage. Each deployed agent encounters unique production scenarios and contributes its learnings back to the central model. The first few issues resolved teach the model basic system topology. The next dozen reveal reliability patterns. By the hundredth issue, the model understands nuances about the system that no individual engineer could maintain in their head.
Which combinations of features and configurations are fragile. Which code areas are high-risk. How different customer segments exercise different code paths.
Critically, this knowledge is durable even as the system changes. When code is refactored or infrastructure migrates, the model retains understanding of behavioral patterns and failure modes that carry forward. A competitor starting from scratch would need to relearn all of this from production experience. They can't simply copy the graph structure, because the value is in the learned patterns encoded within it.
This compounding dynamic is also what makes automated regression testing genuinely preventive rather than merely reactive: when the world model knows which change patterns historically introduced regressions, it can flag risk before the code merges rather than after it breaks.
Why This Leads to AI Production Engineering
If you follow this logic through, you arrive at an interesting conclusion about category structure.
Today, production is stratified by function:
- SRE lives in observability and APM tools
- L1 support lives in Zendesk and Service Cloud
- L2/L3 support and bug tracking live in Jira
- QA lives in test frameworks and CI/CD
Those tools were designed around the functions that had the expertise and context to act on them. But that world is breaking down. The complexity and velocity of modern systems means that sharing context across these silos is often where the real leverage is.
You can easily deflect a support ticket if you understand a change was recently pushed. Infrastructure is easier to diagnose if you understand the software running on it. An SRE incident is much easier to root-cause if you see which customers, flows, and feature flags were affected, and by which deployments. You do better QA when you're testing what actually breaks in production and what customers care about.
This is exactly the dynamic behind support escalations: they happen when siloed tools don't share enough context to resolve an issue at the tier where it first appears. A unified production model changes that calculus. It's also what automated issue resolution looks like when it's grounded in real system understanding rather than surface-level alert correlation.
This points to a different kind of system of record. Not stratified by function, but unified by the fundamental job: understanding and operating how software behaves in production.
We call this Production Engineering — the discipline responsible for understanding how software actually works in production, combining what used to be spread across SRE, support engineering, and QA. From the system's perspective, it's one job: maintaining and operating software after it's been developed.
The concept of Production Engineering has existed for a while, but has never really taken hold. We believe that's because it's simply too complex to run with humans alone. But introducing AI has changed all of this. Now, with a engineering world model, an AI production engineer can reconcile "what we thought the software did" with "what it actually did in production." An AI production engineer can ingest complete context on every problem: support tickets, customer flows, telemetry, code, configuration, tests, and deployments. An AI production engineer can navigate application logic, configuration, and integration defects that cross support, SRE, and QA boundaries.
For a look at how this plays out when the support and engineering sides of the equation connect, see Beyond the IDE: Second-Generation AI Coding Software.
The Path Forward
The companies that build unified engineering world models will have something qualitatively different. Not agents that complete tasks in isolation. Organizational intelligence that compounds. That simulates futures, not just retrieves pasts. That reasons from learned world models rather than starting from scratch.
This is why we started with code simulations. Not because simulation is the product, but because simulation is the test. If you can project hypothetical changes onto your model of production systems and predict outcomes with high accuracy, you've built something real.
If your context graph can answer "what if" with confidence, you have a world model. And if you have a world model of production systems, you've found the foundation for an entirely new category.
The path to economically transformative AI might not require solving continual learning. It might require building world models that let static models behave as if they're learning — through expanding evidence bases and inference-time compute to reason and simulate over them.
The model is the engine. The context graph is the world model that makes the engine useful. And Production Engineering is the discipline that emerges when you actually own how production systems work.