Introducing SIM-1: Models that simulate large codebases and infrastructure for parallel debugging and verificationLearn more →
May 4, 2026
Human in the Loop AI: How to Safely Scale Agentic Workloads with Tunable Autonomy
By PlayerZero Team
Most organizations experimenting with agentic AI run into two barriers long before they reach meaningful automation: the trust gap and the accountability gap.
While teams trust AI enough to summarize tickets and recommend fixes, they do not yet trust it to investigate incidents or implement code changes on its own. And even when AI performs well, this doesn't transfer responsibility—someone still needs to own the decision and be ready to reverse it if it goes sideways.
In mature engineering environments, both concerns are justified. Large codebases, shared infrastructure, customer commitments, and compliance requirements make it risky to let AI move from recommendation to autonomous action without oversight.
That’s why the answer is not full autonomy or full human control—it’s tunable autonomy that you can adjust as you progress in your AI adoption. With this operating model, organizations progressively expand what AI can do as trust grows, all while keeping a clear human owner at critical stages and full control over automated workflows.
The human-in-the-loop problem: why engineering teams stall after early AI wins
Most teams begin with simple AI workflows, like summarizing incidents, explaining code changes, and drafting pull requests. The results are fast, and the downside is low—if the summary is wrong, a human catches it before anything breaks.
Those early wins create pressure to automate more. Leaders begin asking whether AI can take on higher-stakes work, such as classifying incidents, preparing fixes, and closing tickets.
That is where adoption stalls. That's why human-in-the-loop design matters.
Not all AI decisions carry the same weight. The same AI action that’s safe in one workflow can be dangerous in another. Auto-closing a duplicate support ticket carries almost no risk. Auto-deploying a production fix carries enormous risk. The action looks similar, but the consequences aren't.
And a single bad action is recoverable. What's harder to reverse is an agent that executes multiple steps on the same incorrect assumption. Consider an agent that prepares the wrong remediation plan. From there, it validates the wrong outcome and closes the wrong ticket. A small mistake turns into a cascading failure that grows harder to reverse.
The solution isn't to abandon AI altogether. The real leverage comes from building deliberate stopping points into the workflow. These checkpoints create a moment for human review before a mistake propagates, and establish a clear owner for the work that crosses that threshold. Over time, those approvals become the evidence base for every decision that advances AI's role.
The question, then, becomes how to place these checkpoints deliberately—and how to know when you have earned enough trust to remove one.
That is the problem tunable autonomy is designed to solve.
Tunable autonomy: the agentic operating model
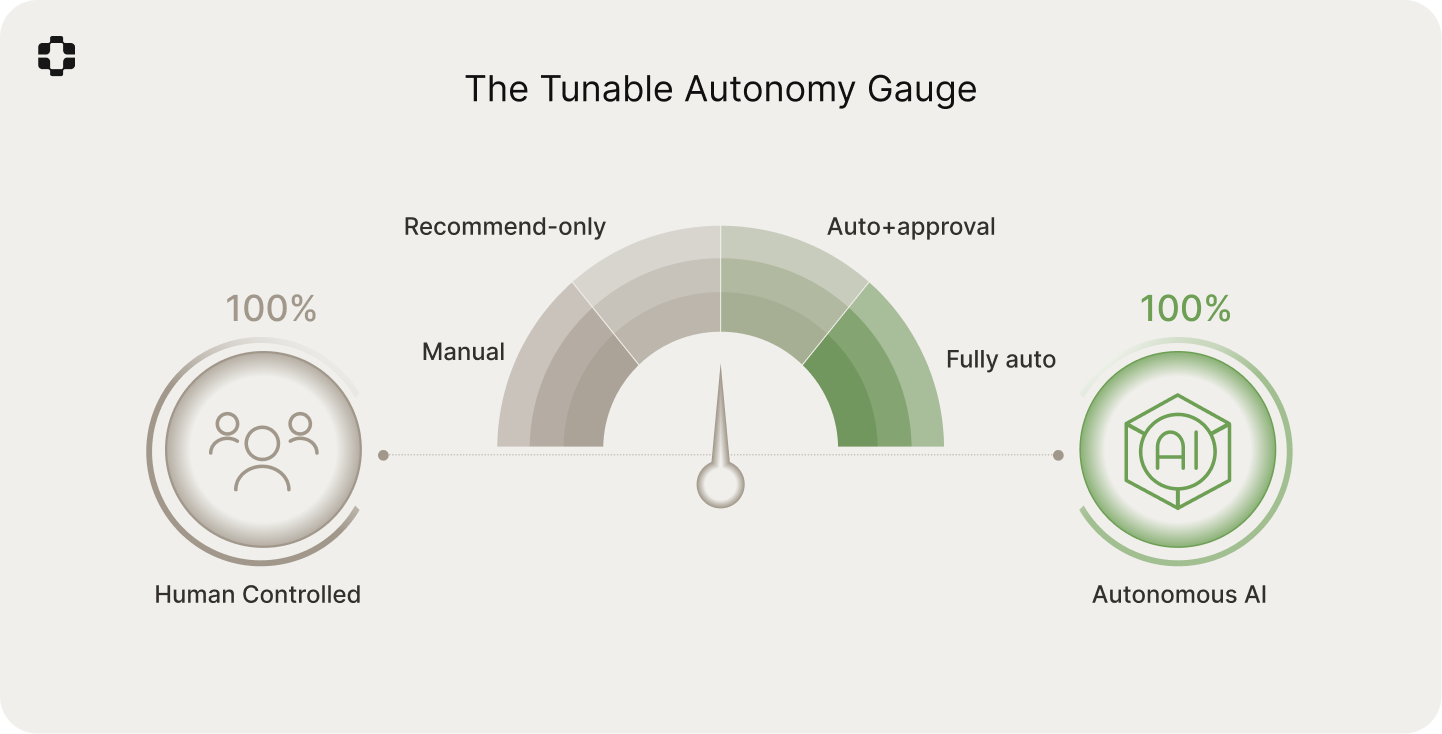
Tunable autonomy gives teams explicit control over how much AI agents can do at each stage of a specific workflow. Rather than making a one-time choice between full human control and full autonomy, organizations can set autonomy levels tailored to each workflow stage.
For each stage, they choose from the four levels:
Manual approval: AI surfaces information, but humans do the work.
Recommend-only: AI suggests actions, but humans approve every step.
Auto-with-approval: AI performs work, but pauses at key checkpoints.
Fully autonomous: AI completes the workflow within defined boundaries.
The following table shows where most organizations start, and where each stage can realistically go.
Workflow stage
Likely autonomy level
Incident triage
Recommend-only → autonomous
Root cause diagnosis
Recommend-only → auto-with-approval
Remediation planning
Manual approval → auto-with-approval
Production changes
Manual approval only
Ticket closure and routing
Auto-with-approval → autonomous
Different workflows should progress at different speeds, and organizations should tune autonomy by repository, service, severity, ticket type, or team.
On transitioning between AI autonomy levels
Setting AI autonomy levels within a team is relatively straightforward. Things get much more complicated when work crosses a team boundary. That's where introducing AI autonomy gates—checkpoints that determine whether AI-driven work can advance to the next stage or domain—matters most.
The reason is simple—each team has different standards, conventions, risk tolerances, and implicit knowledge, so they see the same issue differently. Support sees customer impact, engineering sees code paths, and QA sees reproduction risk.
Say an AI agent is classifying incoming support tickets. The agent’s actions stay within a single team’s domain, so the risk of a misstep is low and contained. When approval rates for AI-driven classifications trend near 100%, that workflow becomes a strong candidate for autonomous operation within your defined guardrails.
Now, say an AI-assisted workflow crosses a team boundary, like an AI-diagnosed issue moving from support to engineering with a recommended fix attached. The stakes rise because the fix comes with root-cause assumptions baked in—if one is wrong, it can travel through diagnosis, remediation, and closure before anyone with the right context catches it. And since engineering has to act on work they didn't produce, accountability for the outcomes becomes ambiguous.
That's exactly where an autonomy gate belongs. The gate ensures the work has been reviewed by someone who can vouch for it before it crosses that line. Each successful handoff, reviewed and acted on without issue, is how AI earns the next level of trust to take on more work.
How to implement tunable autonomy
To implement the tunable autonomy model across your organization, start by establishing full human-in-the-loop approval at every critical stage.
Even in recommend-only mode, AI creates immediate value for engineering teams. Connecting tickets to code, telemetry, and runtime behavior compresses investigation time to minutes. Surfacing likely root causes and recommending fixes streamlines resolutions, increasing customer satisfaction. Drafting pull requests and incident summaries keeps engineers focused on building.
Your team stays in the loop at every step, reviewing and course-correcting before anything moves forward. When their approvals reach close to 100% across workflows, gradually increase autonomy based on the following factors.
Factor #1: Performance data
When you’re scaling AI workflows, you’re not just asking “Can the AI do this task?” but “Can it do it reliably enough to justify less oversight?” Metrics provide the most objective answer to this question.
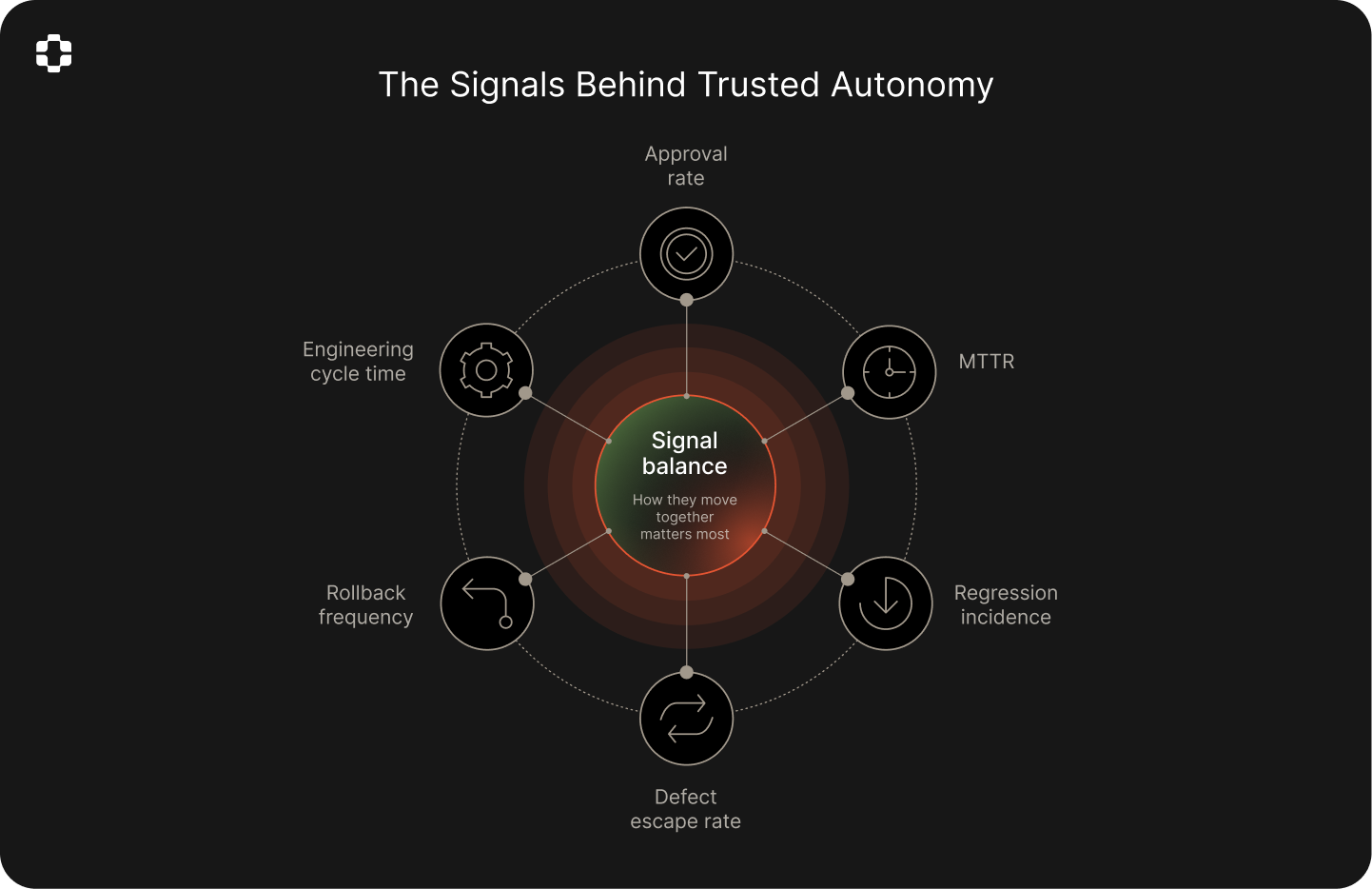
Most engineering organizations already track these metrics for delivery performance and incident management. What changes with AI is what they reveal. Each one now also measures a different dimension of AI’s reliability.
Approval rate: Are humans consistently signing off without overriding?
MTTR: Is resolution time improving as AI takes on more work?
Regression incidence: Are AI-assisted changes introducing new issues into previously stable areas of the codebase?
Defect escape rate: Are issues reaching customers before they've been caught internally, and how often?
Rollback frequency: How often are engineers undoing AI-driven work?
Engineering cycle time: Is delivery getting faster or slower?
Metrics can be gamed or misleading in isolation. The signal that matters most is in how they move together. For instance, a low escape rate suggests that AI passes QA checks—but if it comes with high regression incidence, it means the AI is making changes without accounting for how they affect previously stable parts of the system. On the other hand, if approval rates stay high and MTTR improves without more regressions, autonomy can expand.
Think of it less like flipping a switch and more like a new hire earning the right to make decisions without running them by a manager. Nobody hands over full autonomy on day one. It's granted incrementally by demonstrating sound judgment, catching mistakes before they compound, and building a track record that speaks for itself.
Factor #2: People, process, and context
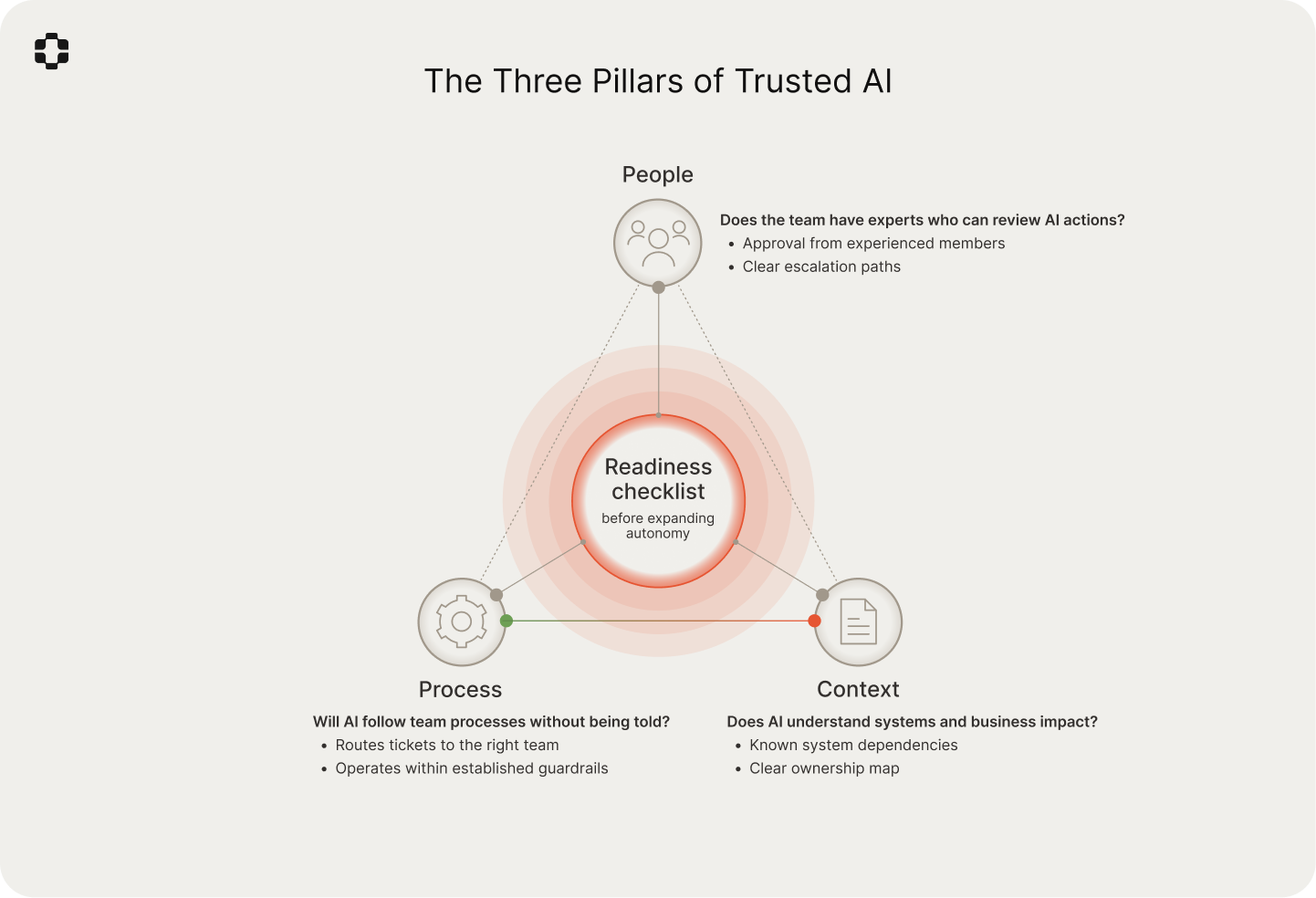
Autonomy can't advance without the professional judgment to back it. Approval from experienced team members ensures AI systems perform well across both familiar conditions and edge cases that only emerge under pressure.
Teams that get autonomy expansion right exercise their judgment across the dimensions where AI has the most influence and the least visibility: people, process, and context. They follow the same three questions before extending AI’s responsibilities further.
Does the AI have enough context on the system and the business to make a decision?
Does the AI know who to involve or escalate to, even if that person isn't a direct owner?
Will the AI follow team processes (e.g., correctly routing tickets) without being told?
While metrics show that trust is building, satisfying these criteria tells you whether it's actually earned. When AI understands enough about your systems, your people, and your processes, it changes how work flows across the organization, increasing resilience and shifting defect resolution from reactive to proactive.
A helpful mental model is to apply the same bar you’d use for a senior engineer. Instead of micromanaging them, you trust that they've internalized the business context, know how handoffs work, and can navigate team processes without a checklist. An AI agent has to earn that same confidence, and teams need to build the evidence that it has.
Key Data’s experience is a blueprint for what it looks like when people, process, and context align with the metrics. By connecting customer-reported issues to the exact code changes and runtime behavior behind them, they eliminated the ambiguity that makes teams hesitant to rely on AI. With that context and the ability to reproduce and diagnose problems in minutes instead of weeks, the confidence to go further with AI across their workflow followed naturally.
The guardrails that make autonomy safe
Safe autonomy depends on strong controls—not just as a brake on what AI can do, but as the foundation that makes expanding its responsibilities possible. Despite differences in scale, stack, and risk tolerance, what those controls actually require tends to look the same across organizations.
The most trustworthy AI systems converge on four properties.
Audit trails: Comprehensive logs capture what happened, when it happened, and why, including model version, confidence scores, tool calls, and reasoning paths. They’re essential for performing post-mortems and detecting behavioral drift.
Attributability: Every action traces back to a specific agent identity, the human or policy that authorized it, and the context in which it acted. This preserves human accountability and enables you to distinguish model errors from policy misconfigurations.
Reversibility: Reversibility caps the scope of any single autonomous action, so no mistake can cause irreparable harm to production systems or data.
Policy constraints: Agents can act outside the spirit of organizational intent. Runtime policy enforcement, like tool allowlists and scope isolation, ensures constraints travel with the agent as it executes, not just at the authorization moment.
While these properties create a foundational audit system that keeps autonomy from becoming a liability, they're not sufficient on their own. Certain actions carry significant organizational weight, making human review essential regardless of how well the AI has been performing.
In these situations, the cost of getting autonomy wrong outweighs the efficiency gains from skipping the review. That’s why a checkpoint there almost always pays for itself.
Work moving between teams: A checkpoint here creates a moment when a person with full organizational context evaluates not just “Is this technically correct?” but also “Is this the right change at this time, for these teams, under these conditions?” That contextual and temporal judgment ensures the quality of the handoff.
Disruptive or hard-to-reverse actions: Disruptive changes like architecture rewrites and dependency upgrades carry asymmetric risk. The blast radius of a mistake is large, and once an action is executed, the window to course-correct narrows significantly. A checkpoint ensures the decision is correct before it becomes difficult to reverse.
The point isn’t to eliminate risk—it’s to make it manageable. AI agents will make mistakes, but they’ll make fewer than their human counterparts. With those controls in place, you can scale or decrease autonomy across teams while keeping errors contained and accountability clear.
At Cyrano Video, the combination of richer context and stronger trust allowed support teams to resolve more issues independently. As a result, the company reduced engineering time spent on support and bug fixes by roughly 80% while preventing many tickets from escalating in the first place.
Why PlayerZero is the right foundation for tunable autonomy
Tunable autonomy only works when AI has access to the full engineering context—but in most organizations, that context is scattered across systems that don't talk to each other, leaving AI to act on an incomplete picture.
PlayerZero creates that visibility by unifying these signals into an engineering world model: a single representation of the system that connects intent, impact, real-world behavior, and institutional knowledge.
That foundation gives AI agents everything they need to meet the three conditions that teams use to validate readiness for higher autonomy: deep business understanding, clear visibility into ownership and escalation paths, and a reliable picture of process execution.
Cayuse shows what this model unlocks in practice. Using PlayerZero, they gave teams earlier visibility into issues and stronger confidence in the accuracy of AI-driven investigations. As a result, they found and fixed 90% of issues before users noticed and cut average resolution time by 80%.
Scaling AI by earning trust, not assuming it
Most organizations treat autonomy as a destination. The ones that scale it successfully treat it as a practice—something earned through evidence, refined through metrics, and extended only when trust is real.
That shift in mindset is what separates teams that adopt agentic AI from teams that build a lasting advantage with it.
PlayerZero is built for organizations that want to move fast with AI—without outrunning their ability to control it—giving teams the foundation to extend autonomy safely and the evidence to know when to go further. Book a demo to learn how.